Refactoring your code
It’s common sense of course to keep your codebase clean all the time, but this isn’t always the case. It simply happens that a codebase grows in ways that were not foreseen on forehand resulting in an unclear architecture or dirty code (that must be the opposite of clean code). In this article I’d like to share our experience in dealing with such a situation, why we needed to refactor, what we did and how it improved our codebase.
Why you need to refactor
Modern software engineering is an agile process, what in short words mean that you don’t try to think through everything on forehand but take small steps. You listen to feedback and therefore are agile to react to the circumstances. This also means that it is impossible to foresee how your app will develop.

Because of this, you sometimes need to look back and evaluate what you’ve built and look critical if the code is something you are happy with. Or you notice while developing that some parts aren’t as you want them to be. But especially when there’s pressure to release a new feature, you don’t always have time to do this.
The example
Our team has been working on an app for about a year, it's a Typescript/React app that handles chatting between customers and customer service or chatbots, while trying to give the user a smooth and pleasant experience. For this example you don’t need to know anything about javascript/typescript/react or what our app does (however some IT architecture knowledge probably makes this an easier read). Although this specific example is on a javascript project, the example is applicable on any software project that got a bit out of hand.
The project started about a year ago as a proof of concept. The results were good and we decided to continue. Over the past year we’ve added a lot of features, both minor changes and big breaking changes. While developing the last few months we had noticed that some of our code was getting hard to maintain and our architecture wasn’t as designed anymore.
The beginning
One of the major architectural decisions for this project was to decouple it from the main webshop (so the actual bol.com). The webshop is a big application with many developers working on it, so minimizing the dependency on it was done to increase the autonomy and the development speed of our project. The only connection was a configuration object that was set as a variable by the webshop, to be picked up by our application. So the architecture of our client side app and its dependencies looked like this:
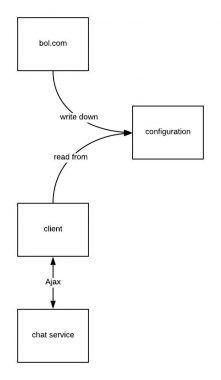
Awesome! This looks simple, and the app can run on every page where you put the initial configuration where the only dependency it has is the endpoint that handles the chat requests is needed, but that’s a given.
Growth
Features were added and our architecture grew by adding the following:
- We needed an element to load the chat app code, was able to initialize the app by setting the initial state and also facilitate communication with the main bol.com UI.
- We stored our data in a redux store, which needed to be backed up in local storage to support multiple tab chat. By doing so, the most recent chat data is present in all open tabs on bol.com, making sure all chat screens keep synchronized.
- We did an additional AJAX call to the webshop for backup data, from the loader element.
Sometimes these features were added without taking the complete architecture into consideration. To be honest, a read from the loader element from the localstorage wasn’t nice (mixed responsibilities) but it was an easy fix for a problem we had, and the data was present and easily accessible in one line of code.
At a point in time our small and simple architecture had evolved to this:
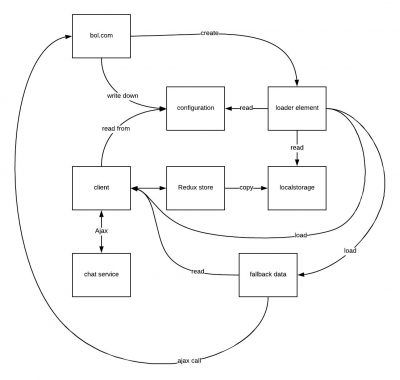
We noticed that we didn’t know exactly what data was modified or read by which component and developing and debugging became harder. Sometimes if we modified a field, we had to do this in multiple places instead of only one. It’s in a programmers nature to hate repetitive tasks, so this didn’t make us happy.
Refactoring
We took some time to rethink this architecture. We checked if all the features were still needed (spoiler: no) and made sure that data was only modified and ready by one responsible component. Actually, rethinking this took only an hour and the implementation of this a day or two, but it resulted in the following:
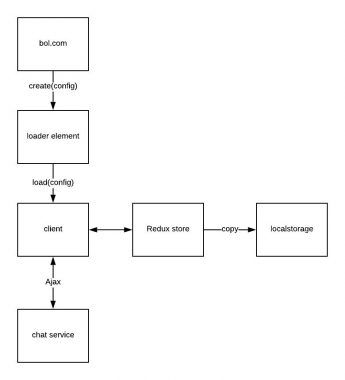
This is a bit more complex than what we started with, but now we do have a local stored redux store, so we don’t need to load all chat messages when a customer is going to a new page. And most of the weird crossing lines are gone! The additional fallback data wasn’t needed anymore since we got this data from the chat service already and the client had fallback data itself, so that was just deleted. A safety net of a safety net was a bit much in this case. By changing the loader element we could just pass the configuration instead of printing it in the DOM. This had the additional benefit that other elements weren’t able of reading it anymore, so this was forcing us to keep a clean separation of concerns.
We also added a new library to our project (as we tend to love as javascript developers), which really improved our codebase. In our case this library solved issues internally that we had to solve programmatically before, so we didn’t need code for that anymore. So it can be a good idea to look around in the technology landscape, maybe a library or framework can save you a lot of time or repetitive code. For us Redux Sagas removed a lot of complexity from the project by handling the ordering of data calls, but I won’t go into detail in this article. Although the implementation of this took quite some time, the amount of code decreased together with the complexity: time well spent!
Refactor prevention
To be clear: I’m not preaching for making a big mess first and then taking a lot of time to clean it up. I’m only saying that it can happen that you made a bit of a mess and should take the time to clean it up and make your application shine again.
It probably takes less time and frustration to keep your application fine on a daily base then to do it in one big refactoring. To use a daily life metaphor: folding your laundry when it is dry is probably a better idea then throwing everything on a pile for months and then have one big cleaning session. Especially if you’re looking for one specific t-shirt that’s one the bottom of the pile...
Books have been written about having a clean codebase, so I’m not going into that subject. But books have been written for a reason: a clean code base is important since it's easier to maintain and nicer to work in it.
Making time
In order to get time to do such a project, that doesn’t add business value directly, it’s important to make sure that the urgency is clear for everyone. A product owner will give more priority to your project if you can demonstrate that future development will speed up due to better code or the amount of bugs will drop due to your refactoring project. In marketing speak: it reduces the marginal cost of new features. I think that transparency about the project and its effects is key to this, in combination with good timing.
One less clear but maybe even more important reason to refactor is developer happiness: engineers that have the chance to get their codebase in tip top shape are probably happier than those struggling in a crappy code base every day. This is an assumption, but certainly true for our team. It is a fact that happy people are more performant, so you can even build a business case on that. For me personally, I find my own happiness very important… naturally.
When there are (tight) deadlines on the horizon, it will probably be much harder to reserve some time for your refactoring stories than in a period when a previous project has just been finished or when people are on vacation. In our case we did release a big feature just before summer, and got some time of our product owner to make our codebase great again!
Conclusion
In an agile environment it is impossible to completely work out a design on forehand. This, in combination with continuously adding features, can result in a codebase that’s not up to your standards. Developing in such a codebase causes more friction and is harder than it should be. It can be best to fix these issues on the go, but if you find yourself to be in a situation where you are dissatisfied with the general state of your codebase, do take a moment to look back and fix it. This minor investment will probably pay back in time saved with a higher development speed in the future and (as a developer, I find this maybe even more important) developer happiness.