Introducing Stanley: bol.com highway to (heaven) BigQuery
Yes, it’s confirmed! Bol.com is going to the Cloud! The contract with Google has been recently signed, which gives us about 1 year to migrate from Platfora (our BI visualization tool), before it stops having support.
1 year thus to migrate many datasets and dashboards to the Cloud. The tools in Google Cloud are great, and our colleagues are too; so, what could possibly go wrong?...
At least this is what we thought in 2017…
Our Big Data situation in 2017
Bol.com was storing its Big Data on Hadoop since 2010. That brought us some good results, but not without some challenges:
- We had to install, upgrade and maintain a Hadoop cluster ourselves
- Our cluster (35 nodes) was too small. It got overloaded and it could take too much time to run some Hadoop jobs.
- As an e-commerce company, we need to have a lot of computational power during the “season” (last 2 months of the year: you know, this moment when you think about holidays and Christmas but when we work extra hard to have all your presents delivered smoothly). Meaning a lot of hardware was not really useful during the rest of the year.
- Multitenancy issues: how to ensure that a huge job does not cause starvation of the resources of some other teams jobs?
- …
Another challenge we faced was to convince our IT teams to publish the data of their micro-services to Hadoop. Those IT teams usually spend most of their time developing their Java-Spring applications, but not very often working with Hadoop, and thus not building knowledge of it. To help them publish their data, we developed “Eddy”, an application that accepts some XML messages and writes that data to Hadoop in a nice format.
In order for the datasets to also be present in Google Cloud, we had to develop a similar tool that would help many teams (more than 50) to publish data to BigQuery (the DataWarehouse component of Google). As an additional challenge, not only should the new data be published, but also the historic data (which can represent some 20 years of data for some teams!).
We called this tool Stanley (yes, we can be very creative at bol.com in finding names!), and we came up with a number of goals.
Goals of Stanley
Before we describe the Stanley design, let’s first discuss the goals we wanted to achieve.
- Standard framework: In 2017 bol.com was still beginning to learn and gain knowledge in Google Cloud. The feature teams didn’t have prior experience with the cloud platform. That meant, without a standard framework available to migrate data interfaces to BigQuery, each team would have to reinvent the wheel. Because there are various possibilities to achieve it, a variety of different techniques would emerge, which would also be a future maintenance hazard.
- Standard datasets: We also wanted to provide standardization across all the interfaces. With standardization, you can think of the naming conventions, datatypes, type of tables, etc. That would eliminate many misinterpretations not only between feature teams but also between IT and business stakeholders. Example of such naming conversion could be the following:
- Should I prefix a field with time as ‘Date’ or ‘DateTime’? Alternatively, should the field be suffixed?
- How should I name technical fields to differentiate them from the functional fields?
- Which datatype should I use to store the identifier of an interface? Should it be a ‘String’ or a ‘Number’?
- When should we use “UTC” or “Local Amsterdam time zone”?
- Ease the integration process: The impact on the roadmap of those teams is not negligible, so we have to make this migration as smooth and easy as possible. It’s not feasible for the teams to migrate their entire service from the bol.com datacenter to cloud immediately. Hence, provide a set of tools to first move the data interface, and then move the rest of the application at a suitable pace.Most of the teams run applications in JVM and use Spring Boot heavily. To ease the migration, we wanted to provide a solution that easily integrates with a standard Java service, and also with the rest of our IT landscape (monitoring & metric platform, deployment framework…).
- Messaging and data interface: The bol.com landscape is full of microservices. Most of those microservices have three different interfaces:
- REST API: For the synchronous communication between the services.
- Messaging interface: For the asynchronous communication between the services by publishing events.
- Data interface: For various purposes, for example for data scientists to train their models and business intelligence for reporting KPI’s.
Each team is responsible for delivering and maintaining those 3 interfaces. In order to do so, they had to develop a separated functionality for each of those interfaces.
What about if we could provide a single framework that could deliver 2 of those interfaces at the same time? Reducing time to market and maintenance required by the team.
Ownership by the team: We learned from previous experience with Eddy, which was centrally managed, that it requires much operational effort and comes at the cost of innovation. Hence, unlike Eddy, we wanted to give teams the full ownership and control over their interfaces. By giving them the ownership, they are also responsible for the quality of data they provide. In this way, teams have direct control to take action (if required) to improve or adjust their interface.
Stanley Design
Now let's take a look at Stanley architectural design to achieve the above requirements and more.
As mentioned before, the goal of Stanley is to help scrum teams provide data and messaging interface of their services in the cloud. All events are published to Google Pub/Sub; after that, they are processed to be stored in Google BigQuery.
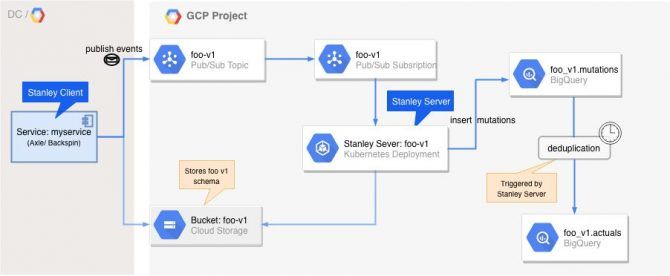
Stanley consists of two parts:
Client: The client is a Java library to be used within a service. Whenever an interesting event happens in a service (e.g. "Order created", "Email sent"), this library can be used to publish the event to a Pub/Sub topic.
Server: The server is a standalone Spring Boot service, managed and deployed by the team. It listens (by creating subscription) to the Pub/Sub topic that is filled with events by the client. It then takes these events and stores them in BigQuery. The server is deployed in the cloud in Kubernetes.
The BigQuery part of the interface is composed of 2 types of tables:
- All the events are permanently stored in a BigQuery mutations table, so you can easily replay them or use them for initial loads of other services. Worth to mention that in this mutations table, the full information of the “event” is given (aka: you have the whole “object”, not just a “diff” from the previous mutation).
- The events are deduplicated into a BigQuery actual table so that people can easily see the current state of each entity without having to read all the history from the mutation table.
Here is an example of a mutations table (left side) and an actual table (right).We can see that the actual table only contains the last status of each Object (identified by the “_Stanley_Entity_Key”). The object “gid_17” does not appear in the actual table because its last mutation states that we want to delete this Object.

Why not Dataflow?
When you read the above requirements and design, obviously you would say why not use Dataflow? And that’s a very valid point; perhaps that would have reduced some complexity. However, we saw challenges with the adoption of Dataflow across all the teams. As mentioned earlier, teams work mostly with the Spring Boot applications; they didn’t have enough experience with Dataflow, which has a steep learning curve. That would make it challenging for teams to really take ownership.
Once again: what could possibly go wrong???
Well, a lot of things… as usual in IT.
So, let’s see how features in Stanley help teams to debug and make their life easier.
The first thing to look at when in trouble: the web interface! It displays the status of the current situation (here below we can see that everything is green J ), some links to other useful services (like our Kibana logging server) and other extra information:
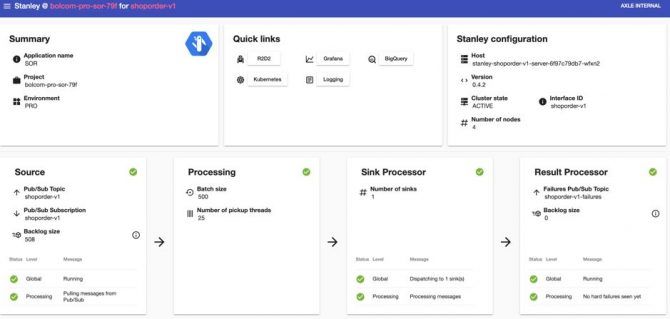
And what if some data corruption occurred?
No problem, Just check the content of the “Failure Pub/Sub Topic” (bottom right on the image)! This queue captures the incoming messages that the Stanley Server does not manage to save into our BigQuery table. That happens for instance if the messages have a schema that is not compatible with the DDL of the BigQuery table. With this Failure Topic, the IT teams have the opportunity to read the messages that have failed, to apply the necessary fixes, and to republish those messages to Stanley again.
And what if I hit some quota limits in Google?
Yes, that happens: Google sometimes makes it a bit complicated. Well, their solutions present what is called “quotas”. Just like this one about the maximum number of partitions in a single BigQuery table (quota 4000 ). 4000 partitions-days is obviously too low when we want to store 20 years of data in a table. Fortunately, Stanley allows us to “split” a table. Either per year, per month or per week. 3 more configuration lines more to write, and problem solved!
And now that everything seems stable and perfect, and that you are about to relax and spend some time thinking about the topic of your next Hackathon, you suddenly see some people looming at your desk: Business people. With some new requirements for your dataset. With a bit of luck, they will only ask you to add a new column to your BigQuery table. If this column can contain NULL values, then this is a “compatible change”, and that can be easily tracked with a “minor update” of the schema.
Basically, that means that you just need to add one column in your Java Schema class, deploy your new code, and then push the “upgrade” button in the Stanley web interface.
Talking about the Schema, let’s have a quick look to see how easy it is to define it in our code:
Schema<Order> myOrderSchema() {
return Schema.builder(Order.class)
.title("order")
.version("1.0.0")
.description("Orders processed by the service")
.column(Long.class, "orderId", "The ID of the order", Order::getId)
.optionalColumn(Integer.class, "retailerId", "Which retailer had the order", Order::getRetailerId)
.repeatedColumn(String.class, "globalIds", "Which global id's are used", Order::getGlobalIds)
.repeatedColumn(Order.Item.class, "items", "Items inside the order", Order::getItems, schema -> schema
.column(String.class, "description", "Description as printed on the label", Order.Item::getDescription)
)
.build();
}As you can see, it is possible to specify columns that are Nullable, Required or Repeated. Records are also allowed, meaning we can create a nested structure as complex as BigQuery allows us. All the BigQuery types are also supported.
The last argument of the “column()”, “optionalColumn” or “repeatedColumn” methods specify the method that will be used to fetch the related information when we “publish an object”.
Publishing an object means that the Stanley client sends the data of the whole entity to PubSub, which will be consumed some few milliseconds after by the Stanley Server in order to be inserted into the BigQuery mutations table.
Here is an example that shows how to publish a mutation:
public void publish(Order createdOrder, Instant orderCreatedAt) throws IOException {
client.publish(Envelope.builder(Order.class)
.schema(myOrderSchema)
.entity(createdOrder)
.entityKey(String.valueOf(createdOrder.getId()))
.mutationTime(orderCreatedAt)
.mutationType(MutationType.CREATE)
.build());
}Every time the Stanley client publishes an entity (in our example, the “createdOrder” instance), we have to associate the Schema created above, and some few Stanley “metadata information” like the mutation time for instance.
What’s next with Stanley?
Stanley has been adopted by many teams at bol.com and as contributors to this project, we are proud to see how it has helped the organization to move to the cloud faster.
However, Stanley is not yet finished and there are many improvements we would like to add. Some of them being:
- Integration with our Data Quality checkEach team has the possibility to deploy in the Cloud a Kubernetes service that checks that the data in BigQuery is in sync with the data they have in their Postgre OLTP In order to simplify deployment and to encourage teams to use this Data Quality check, we want to integrate it into Stanley.
- Add new BigQuery functionalitiesBigQuery keeps improving too, and Stanley needs to catch up. Features like “clustering” need to be added to Stanley.
- Snapshot possibilitiesThe “actual table” allows people to know the current situation for a set of specific entities. However, some business use cases require sometimes to know the situation on a specific day in the past. That is why we have started to add a “snapshot” feature: Stanley provides a 3rd BigQuery table, where each day at midnight we take a copy of the data in the “actual” table, and we store it in a new partition of that table.
- Add more data sinksCurrently, the data that is pushed into a PubSub topic by the Stanley client is only saved into BigQuery. But it could be interesting to also consider other Google Cloud technologies, like for instance Datastore, Spanner etc.
And surely many more ideas will pop up in the future! What we have seen so far is that the cloud gives all the teams (both IT and Business teams) a new way of working, more capacity and speed to process data. Based on that, new ideas start to pop up that lead to new requirements for Stanley.
Stanley has gone a long way so far, but this is just the beginning of the journey! We would like to thank all the earlier members of the Stanley team and new Falcon team who are taking Stanley in maturing the product to the next level.