The hyped, happening and happened cloud technologies and data storage solutions @ bol.com
We asked 25 developers, five tech leads and someone “who does unspeakable things with technology” - more commonly known as our principle tech lead which technologies (tools, libraries, language or frameworks) they believe are hyped, happening or happened:
- hyped - which new technologies are you eager to learn more about this year?
- happening - are there any exciting technologies you used last year that we should learn this year?
- happened - did you walk away from any technologies last year?
This is what we got back:
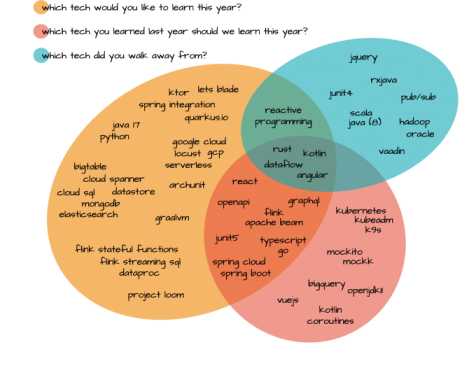
This blog post, which is part of a series of six blog posts in total, we have a closer look at cloud technologies and data storage solutions:
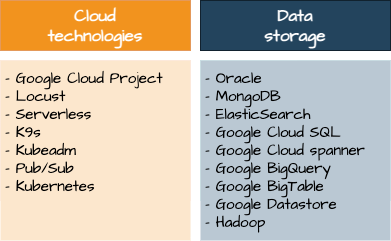
Here you can find a complete overview of all blogs in this series.
Google Cloud
We have been on cloud nine ever since we spun up our first application in Google’s cloud. Nowadays, bol.com runs a vast amount of new and existing applications in the sky. The Google cloud project offers a rich tech stack. The responses which contain a variety of cloud technology reflect that. Here we only describe a few cloud technologies. Of course, that does not do justice to the overwhelming amount of useful tools the cloud brings.
Before we dive into the next two tools, however, we first need to explain to you a little bit about Kubernetes. Just in case you don’t know what that term means.
Kubernetes
You build it, you run it, you love it - a phrase often heard and practiced within bol.com. As we’ve already shown, we build our applications with various programming languages. When it comes to the cloud, we run and manage our applications with Kubernetes - also known as K8s and we use Docker to create containers for our applications.
As a container management system, Kubernetes helps us deploy and run containerised applications in the cloud. With Kubernetes we don’t have to worry about which physical machine our container runs on. We don’t even have to worry when this machine dies. Kubernetes will automatically detect this and spin up a new application instance for us. With the right configuration Kubernetes is even capable of scaling our applications automatically based on CPU usage or other metrics. (See for example here how kubernetes can save you headaches and money). Kubernetes takes away all of these and other challenges for us and that’s why we love it.
Kubeadm and K9s
Now that you are all hyped up about using kubernetes, and have already created your container, you might be wondering how you can create a kubernetes cluster to deploy your container in. Kubeadm allows you to set up a minimum viable cluster on an existing infrastructure by configuring and starting up all required kubernetes components. This allows you to quickly set up a kubernetes cluster which allows services to talk to the kubernetes API.
Kubernetes is getting more complicated by the day, and one needs to learn a wide variety of commands/tools for monitoring deployments, updating configuration, troubleshooting, etc. What if there was a simple way to interact with your clusters, to navigate, and observe them? K9s offers this and much more. It is basically a terminal UI which continuously monitors kubernetes for changes and offers simple ways to interact with the resources. The best thing about K9s is that you can do most things with very simple commands. You have a UI which gives an overview of the clusters and namespaces and allows you to switch between them with ease. It also allows you to check logs, track real time metrics, and it even has a built in load generator to test the performance of your service! All in all, it’s a very helpful tool for developers using kubernetes.
Serverless
Before the serverless revolution, anyone who wanted to create a web application needed to own a physical computer which could run a server, which was cumbersome and expensive. These days, companies need a lot of on-site servers to be set up to run applications. Provisioning and maintaining a server is slow and knowledge about the underlying systems is required, which slows down development time. However, this can be mitigated by opting for a serverless platform.
Firstly, what is a ‘serverless’ platform? It is nothing more than a server, except it is managed by a third party - and we at bol have opted for Google Cloud Platform (GCP). So the serverless vendor provides the services we request for, without us having to worry about setting it up and the hassle of understanding the underlying infrastructure.
A serverless architecture has several advantages over an on site server, such as:
- No server management - no need to maintain the server periodically and update its software. The vendor takes care of all this.
- Automatic scaling - The server scales up its resources automatically when the incoming load increases. It scales down when the load reduces.
- Cheaper - You usually only pay for the features being used, unlike the on-site servers which are running 24/7 where you pay for idle CPU time.
There are also a few drawbacks, such as:
- Third party dependency - you are completely relying on an external vendor to run all your applications and you don’t have full control over the server. Sometimes breaking changes are released which could impact your service.
- Performance may be impaired - since the third party server is shut down when it’s not used, it requires some time to boot up and causes a ‘cold start’ which causes an initial delay in the requests it’s handling.
Pub/Sub
Modern day applications adopt the microservice architecture, which results in many small services which communicate with each other. These services need to handle a lot of requests every second and need to process them very quickly. At the same time they have to be highly available for new requests. A messaging queue decouples the services from each other. This allows the producer service to add messages to the queue without having to wait for them to be processed. Consumers will then handle these messages one by one in their own time.
Publish/Subscribe (Pub/Sub) is one such queuing mechanism provided by Google which allows async service-to-service communication. Using Pub/Sub has numerous advantages, such as:
- No polling - this is very advantageous for services that rely on real-time events, since messages can be pushed to the consumer instantly, rather than the consumer periodically pulling the topic for new messages. This results in faster response times and reduces latency.
- Decoupling and independent scaling - Publishers and subscribers are completely decoupled which allows them to work independently, and they can also scale independently.
- Reliable delivery - Pub/Sub delivers a message at least once per subscription. If the consumer service is down for a few minutes, it will not miss any messages since it can process it once it’s back up.
However, there are still some disadvantages which might lead to companies not adopting Pub/Sub:
- There is no ordering guarantee for the messages - this could really affect systems where their business logic relies heavily on the order of the message received. Or as one of our tech leads pointed out:
pubsub does not guarantee ordering at all. <...> It is even worse than what you would expect from the IKEA ball pit <...> with lots of kids throwing the balls around.
- At least once delivery - since message may be delivered to the consumer more than once, deduplication logic is needed on the consumer side
- Overkill for smaller systems - Pub/Sub is not the ideal choice for a simple system where scaling isn’t necessary.
Locust
When running your applications on a Kubernetes cluster in the cloud, scaling your applications becomes a breeze. Wouldn't it be great if we could scale our performance tests just as easily to generate any load imaginable? With Locust you can do just that.
Locust is a fully distributed performance testing tool. It is written in Python and allows you to write your performance tests also in plain Python. By deploying Locust Docker containers on a Kubernetes cluster you can generate load for your application in a scalable way. No wonder we can find Locust amongst the popular tech.
Data storage
Large number of applications have some state and are likely to depend on data storage. Here we walk you through a few of them.
MongoDB
MongoDB is a powerful, distributed NoSQL database that stores its data in a Json-like format with or without a schema. It “makes database modelling and model-related issues a thing of the past, simplifies DAO layer to a few lines of code is a clustered database with 0 downtime.” . No surprise that it is popular.
Elastic Search
ElasticSearch is an open source search engine which has extremely fast search response times. It is able to achieve this because instead of searching for the text directly, it searches for the index instead. This allows it to query billions of records in just a few seconds. It has some other advantages, it is:
- able to run on multiple platforms since it is developed in Java
- highly scalable, and the scaling process is automatic and trivial
ElasticSearch is a powerful and flexible data storage platform, but it does have a steep learning curve. But once you get the hang of it, you will begin to marvel at its speed.
Cloud data storage
The Google cloud offers a myriad of ways to store your data, some of which could unlock interesting features that were not available to us before. For example, Cloud spanner which
“could unlock significant potential our high volume systems.”
Cloud Spanner, Cloud SQL, BigQuery, Datastore are just a few of the data storage options you can choose from the Cloud menu. Each storage type has its own pros and cons. Especially when it comes to the nature of your data and your querying needs. And then we didn't even mention cost, security, reliability, consistency and performance. All these things to consider when picking the right storage for the job. Really, we could spend more than thousands of words on this topic alone. But a picture says more than a thousand words. So, we let this decision chart do the talking:
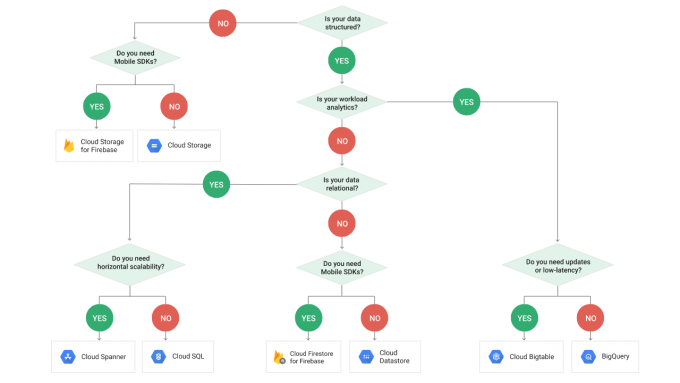
(https://medium.com/google-cloud/a-gcp-flowchart-a-day-2d57cc109401)
Oracle
Oracle is the database management system we heavily used for storing our data on-premise. But not anymore. It requires specialised skills to install and maintain an Oracle database. For us, Oracle is not cost-effective, because you pay for the resources you need to cope with the peak load. Seeing as most times of the year are not that busy, you’re typically paying too much. Compare that with the ready-to-use, don’t-have-to-maintain and pay-as-you-go data storage options the cloud offers. It is almost an unfair fight, isn't it?
So, as one developer puts it: “no.” (Ok, this is completely ripped out of context, but the point should be clear.)
Hadoop
At bol.com we had an on-premise Hadoop cluster running for a few years to quench our big data thirst. We fully replaced our Hadoop cluster with Google's cloud big data technology that is cheaper, takes little (no) effort to maintain and is easier to scale.
Want to read more about hyped, happening and happened tech at bol.com? Read all about The hyped, happening and happened async programming and streaming frameworks @ bol.com or go back to The hyped, happening and happened tech @ bol.com for a complete overview of all the hyped, happening and happened tech at bol.com.