How to prevent common performance defects with the jPinpoint PMD rules
Prevention is better than cure - a fundamental principle of health care that also applies to modern software development. The later a bug surfaces, the more effort it takes to repair. From our own experience we know that this especially applies to performance bugs. So, wouldn't it be great if we no longer have to cure our application's poor performance, because we prevent common performance defects?
jPinpoint's PMD rules can do just that. If you followed the Performance Aware Java Coding workshop we have at bol.com, or have seen this at a NLJUG conference, these rules and best practices will be familiar to you. If you haven’t yet, it is time to get introduced to them.
Of course, we carefully check the results of our daily-run performance tests before deploying any new functionality to production and we have automated checks in place that trigger an alert when our application does respond slowly. So, if we would have anything to improve, then we would know about it, wouldn't we? In this blog post we let the jPinpoint rules be the judge of that. We present our first experience with applying the jPinpoint rules to one of our projects that runs in production. In particular, this blog post will:
- Introduce you to the jPinpoint rules - how and why were they created? Where can you find them and how can you use them in your own project?
- Give you an impression of what the jPinpoint rules can do for you by elaborating on some performance defects the rules found in our code.
- Give you a feeling of what the jPinpoint rules cannot do for you by discussing some of the tool's limitations.
- Answer the question of whether we can stop curing our application’s poor performance if we use the PMD jPinpoint rules.
Introducing you to the jPinpoint rules
Before we dive into the possible performance caveats we detected in our code, let's first introduce you to the how, why and what of these rules.
How and why the jPinpoint rules were created
Who can explain better than the author himself how the jPinpoint rules were created? So, here is what Jeroen Borgers, the main author of the jPinpoint rules, has to say about them:
The purpose of the jPinpoint rules project is to create and manage automatic ava code checks.We categorised many performance pitfalls based on our findings in practice in the last decade. The following sources formed the basis for this: performance code reviews, load and stress tests, heap analyses, profiling and production problems of various applications of companies.We automated several of these pitfalls into custom PMD/Sonar jPinpoint-rules. Each pitfall comes with best practice solutions.You cannot find these checks in other places, like the standard PMD, FindBugs/Spotbugs, Checkstyle or Sonar rules. We offered these rules to the PMD-team for inclusion in the standard rules and we were warmly welcomed. We have been working with them to upgrade and merge (some of) the jPinpoint rules in the standard.
The jPinpoint rules can detect common mistakes that could hurt our application's performance as early as the development phase. And that's why the jPinpoint rules were created.
How to install the jPinpoint rules
You can find jPinpoint PMD rules in this GitHub repository. The readme covers everything about how to install and use the rules in your own project and how to contribute to the project.
The rules are specifically tailored to the PMD static source code analyzer. This means that you need PMD to run the jPinpoint rules. There are multiple ways to use PMD, you can run it as a Maven or Gradle task, from the command line or you could use a PMD plugin for your favourite IDE. (That's IntelliJ for us, but it also supports other IDEs.)
We chose to use IntelliJ's PMD plugin, because we find that the easiest way to run and use the jPinpoint rules. Installing the jPinpoint rules after you installed the PMD plugin is easy and is explained here.
How to use the JPinpoint rules
Once you follow the instructions to import the rules into the PMD plugin, unleashing the rules on your code base is just a mouse click away. This is what that looked like in our project:
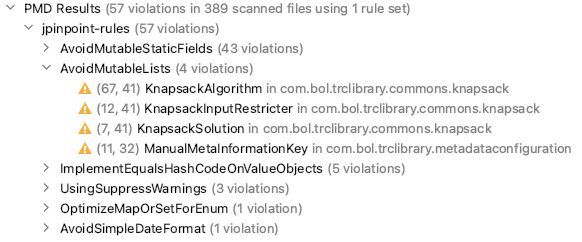
As can be seen, the PMD jPinpoint performance rules found 57 violations in total. These violations are grouped per rule type. For example, we violated the AvoidMutableLists rule four times. (What that means we'll explain later.)
Double clicking on a violation takes you directly to the line of code that is the culprit. Right clicking on it gives you two options:
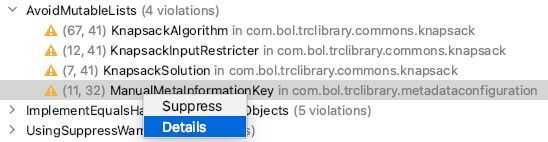
Clicking on 'Details' is definitely something we urge you to do. It takes you to the documentation on the GitHub project, which gives you a detailed explanation of the detected performance concern and possible ways to fix it.
Clicking on 'Suppress' adds a comment to the line where the suspicious code was found. This instructs PMD to ignore this violation in the future, e.g.:
//NOPMD - suppressed AvoidMutableLists - TODO explain reason for suppressionSuppressing warnings should not be done without a second thought. In fact, PMD won't let you off the hook that easily. It added a TODO that invites you to at least explain why you chose to click on that 'Suppress' button. But, as we shall see later on, there are cases in which suppressing warnings might come in handy.
What the jPinpoint rules can do for you
The jPinpoint PMD rules consist of 91 different rules and more rules are added every month. So, it did not surprise us that PMD found quite a few violations in our code. In what follows we elaborate on some of the most interesting issues. Thereby, we hope to give you an impression of what PMD could mean for your project. As a bonus - just like us - you might learn some new good practices to boost your application's performance.
Unconditional operation on log argument
To warm up, let's start with a best practice we - and so might you - already heard of. That is, avoiding the unnecessary invocation of expensive operations in log statements. Knowing is one thing and doing is another, so it seems. Because PMD spotted a handful of places where we ignore this best practice, for example:
if (brandPage.getPartyId().isEmpty()) {
logger.debug("Brand page party ID is empty! Full Request payload: {}", brandPage.toString());
}This code always executes the toString() method, even when the log level is set to info or lower. This might seem rather harmless to you, but even this simple toString() method involves concatenating quite some fields. Besides, this waste of resources can be easily avoided by adding logger.isDebugEnabled() to the condition of the if-statement. Or, even better, use parameterized log messages.
Avoid mutable static fields
Let's continue with a potential performance mistake that was found often in our code, but was relatively easy to fix. PMD tells us that we use static mutable fields in quite a few places, while we shouldn't. Take for instance this example:
private static String DASH = "-";Of course, since a dash will always be the character '-' we should have declared this variable as a constant:
private static final String DASH = "-";This already satisfies PMD that immediately stops to complain about this line.
But why does PMD complain about this line? A single right click on the violation and another left click on 'details' takes you to the online documentation. There you can find your answer: "Multiple threads typically access static fields. Unguarded assignment to a mutable or non-final static field is thread-unsafe and may cause corruption or visibility problems. To make this thread-safe, that is, guard the field e.g. with synchronised methods, may cause contention."
In our particular case, nobody should change our static field, ever. So, there is no risk of corruption and visibility problems and, therefore, also no need for (performance degrading) synchronised methods. We only should have indicated that by marking the field final. And, this is exactly what the documentation advised us to do: "Usually 'final' can just be added to prevent concurrency problems."
Avoid mutable lists
Closely related to the use of static immutable fields is the use of mutable lists for storing data. Consider, for example, the following violation the jPinpoint rules detected in our code where we store the combination of a language as spoken in a country:
public static final List<Pair<Language, CountryCode>> NL_COMBINATIONS = new ArrayList<>();
static {
NL_COMBINATIONS.add(Pair.of(Language.nl, CountryCode.NL));
NL_COMBINATIONS.add(Pair.of(Language.nl_BE, CountryCode.BE));
}The problem with this code is that someone could add items to this list without being aware of the problems it may cause. As you can see we store the list statically, meaning that it typically stays in memory forever. So, this list could potentially grow without restriction and become a memory leak.
We deem this particular case to be an actual risk, because the list is publicly accessible - we have no control over how other code uses it.
Following the suggested solution to "make the field immutable and final" leads us to the following fix:
public static final List<Pair<Language, CountryCode>> NL_COMBINATIONS = ImmutableList.of(
Pair.of(Language.nl, CountryCode.NL),
Pair.of(Language.nl_BE, CountryCode.BE));Object Mapper created for each method call
So far, PMD mostly caught us neglecting good practices we - and so might you - are already acquainted with. The following violation, however, involves something that was new to us. It involves the first line of this method intended for creating a JSON string out of any object:
public static <T> String toJsonStrings(T entity) {
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setSerializationInclusion(JsonInclude.Include.NON_NULL);
return objectMapper.writeValueAsString(entity);
}As can be seen, we instantiate a new object mapper on each method invocation. And according to the jPinpoint rule that should be avoided, because "ObjectMapper creation is expensive in time because it does much class loading." As you can probably guess, this generic utility method is invoked quite often.
Luckily, we can follow the recommended approach "to create configured <...> ObjectWriter<> from ObjectMapper and share those, since they are immutable and therefore guaranteed to be thread-safe." (ObjectMappers are not fully thread-safe, so better not share those objects.)
Following this advice turns our code into this:
private static final ObjectWriter objectWriter =
new ObjectMapper().setSerializationInclusion(JsonInclude.Include.NON_NULL).writer();
public static <T> String toJsonStrings(T entity) {
return objectWriter.writeValueAsString(entity);
}And that makes both us and the jPinpoint PMD check happy.
Optimize map or set for enum
To finish our discussion on what the PMD JPoint performance rules can mean, let's have a look at one last example of a performance defect we weren't able to detect ourselves:
Map<Language, ProductInformation> productInformationMap = pcsAdapter.getProductById(...);Here we acquire all translations for a product from an external service and store them in a map of product information per language. The crux here is that the key we use, Language, is an enum predefining all languages we support. As the documentation of this jPinpoint rule tells us, however, we better use an EnumMap over a HashMap that is "rather greedy in memory usage." An EnumMap on the other hand, "is represented internally with arrays which is extremely compact and efficient."
What the jPinpoint rules cannot do for you
If you're not convinced of all the good things the jPinpoint PMD rules could do for you by now, then please have a look at all the pitfalls and best practices the rules cover. What we covered here is only the tip of the iceberg really.
Having that said, we also like to show you a few examples that illustrate what the jPinpoint rules cannot do for you (yet). We hope this will guide you on how to use the rules so you'll get the most out of them. In the following discussion we give some examples that show that the jPinpoint PMD check cannot:
- detect all possible performance defects, i.e. false negatives;
- always judge how severe a performance issue actually is;
- always tell you how to best fix a problem.
Before we discuss all these cases, however, we first show you that the rules sometimes detect problems that are actually not there, i.e. false positives.
Is this actually a performance problem?
Did you notice that we forgot to tell you how we solved our usage of the memory-inefficient HashMap for storing enum keys? We will now.
Following the advised solution boils down to replacing the HashMap on this line:
Map<Language, ProductInformation> productInformationMap = pcsAdapter.getProductById(...);by an EnumMap:
EnumMap<Language, ProductInformation> productInformationMap = pcsAdapter.getProductById(...);This won't compile, however, because the getProductById method returns a HashMap. So, we either have to convert the HashMap to an EnumMap on this spot or we have to change getProductById's to return an EnumMap. Let's do the latter, because in all places where we call getProductById we likely have the same violation.
However, Java's standard EnumMap is mutable and we prefer immutability. Therefore, we adapt the getProductById method to create a Guava immutable enum map rather than a HashMap:
return Maps.immutableEnumMap(productTranslations);The only thing left to do now is to change the method's return type to EnumMap. But wait a minute, that won't compile. Guava's immutableEnumMap returns an ImmutableMap that is backed by an EnumMap. Even though this instance of ImmutableMap still outperforms a HashMap by far, an ImmutableMap is not an EnumMap. And that's why the compiler complains if we change getProductById's return type to EnumMap.
So what's the problem, you say? Didn't we overcome this performance pitfall by changing only one line and without having to change all the places in which we call the getProductById method? Yes, that is true. Sadly, the jPinpoint rules don't give us credits for this. Instead, the same rule still triggers on every line where we invoke the getProductById method.
Remember that 'Suppress' button that allows us to suppress these kinds of violations in the future? Good, because this is an example of when its use is justified. Or better yet, we create a fix request to support immutable enum maps in the future: https://github.com/jborgers/PMD-jPinpoint-rules/issues/166 and https://github.com/jborgers/PMD-jPinpoint-rules/issues/167.
Isn't this actually a performance problem?
The previous section describes a case of a false positive. That is, the jPinpoint rules indicate a potential performance issue, while there is none. In this section, we have a look at the opposite. We show you a case in which there actually is a performance risk that remains unnoticed, i.e. a false negative.
Recall the previously discussed case in which we forgot to mark the following field as final:
private static String DASH = "-";The PMD check kindly drew our attention to our little mistake. Similarly, the PMD check reminded us of the fact that we should avoid using mutable lists, which we accidentally did here:
public static final List<Pair<Language, CountryCode>> NL_COMBINATIONS = new ArrayList<>();The underlying lesson here is that in general one should consider using immutable objects over mutable objects. Of course, there is much to say about this and this a good read to start with if you didn't embrace immutability already. For what follows, however, we do assume that in aforementioned examples immutability is the way to go.
Next, consider this example in which we statically store the books category:
private static Category BOOKS_CATEGORY = new Category("8299", "books");This is an example of a mutable field, do you agree? Indeed, the jPinpoint rules will complain that we use a static mutable field. But what if we make this field final, e.g.:
private static final Category BOOKS_CATEGORY = new Category("8299", "books");Would that solve the problem? If this object itself is immutable, it does. If, however, we can still change the Category object after creation, it would still be thread-unsafe. To fix that we should either make it immutable too or guard it with, e.g., synchronized methods that in turn may cause contention.
For the most popular types (including Guava) the rules just know if they're (im)mutable. That does not hold for custom objects, however. That is, even when the Category is mutable, no rule will tell you so.¹
Perhaps not the best way to fix this?
The suggested solutions the jPinpoint rules provide give some great advice on how to overcome performance defects. That we should not blindly follow that advice all the time, though, becomes clear from the next example.
Consider another usage of mutable lists the rules found in our code:
ManualMetaInformationKey(..., List<String> refinementValueIds) {
...
this.refinementValueIds = refinementValueIds;
}If, again, we follow the suggested solution to "defensively copy the modifiable argument, so also the caller is not able to modify the object referenced by the field anymore" we would end up with the following code:
ManualMetaInformationKey(..., List<String> refinementValueIds) {
...
this.refinementValueIds = ImmutableList.copyOf(refinementValueIds);
}Closer inspection, however, shows us that this constructor is invoked frequently. Defensively copying the list would create a lot of copies. Redundant copies, that is, because all the code calling this constructor already passes in an immutable list.
So, changing the constructor signature in such a way that it only accepts immutable lists would be more efficient, don't you think? Indeed, this fix no longer triggers the jPinpoint rule:
ManualMetaInformationKey(..., ImmutableList<String> refinementValueIds) {
...
this.refinementValueIds = refinementValueIds;
}Is this a big problem?
The PMD tool statically analyses your code to detect possible performance flaws. It has no notion of how often a certain piece of code is executed. As a consequence, it cannot judge what the actual performance impact will be of a detected flaw. To explain this further, consider the following code snippet:
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("class ProductPageContext {\n");
sb.append(" globalId: ").append(toIndentedString(globalId)).append("\n");
sb.append(" productTitle: ").append(toIndentedString(productTitle)).append("\n");
sb.append(" canonicalParameters: ").append(toIndentedString(canonicalParameters)).append("\n");
sb.append("}");
return sb.toString();
}This jPinpoint rule tells us that "reating a StringBuilder and using append is more verbose, less readable and less maintainable than simply using String concatenation (+). For one statement resulting in a String, creating a StringBuilder and using append is not faster than simply using concatenation."
The question is, if this really is a (big) problem? Without any exaggeration we can say that rewriting the code will be a problem, seeing that we did not write this code ourselves. In fact, this toString method was autogenerated by the OpenAPI Tool Maven plugin.
So again, do we risk a performance issue here? No, we're safe - we don't use this toString method anywhere in our project. In this case we decided to ignore the jPinpoint rule's advice.²
Of course, this example is a no-brainer. It takes a high amount of effort fixing this defect without any gain. The point is that for every performance defect you should assess if the costs of fixing the possible defect outweigh the expected performance gain. In any case, the jPinpoint rules cannot help you make that decision.
Conclusion
In this blog post we introduced you to the PMD jPinpoint rules that can detect possible performance defects by statically analysing your source code. We gave you an impression of what the rules can do for you by giving some examples of actual defects detected in our project. And, we also gave you a sense of some of the tool's limitations.
To answer our previous question: Now that we have the jPinpoint performance rules to watch our back, do we still have to worry about curing our application's poor performance? It might not surprise you that the answer to that question is a resounding no! Even though it does a great job at detecting tons of possible performance pitfalls, you shouldn't rely on it to find every defect in your code. Neither should you take every flaw for granted. Always remain critical about the severity of a detected flaw and how to fix it, if at all. The tool is there to think along with you, but you still need to do the thinking!
Having that said, the jPinpoint rules are a great addition to your software delivery process. They help you find and fix performance defects early on and before they end up in production. They may improve your code and, thanks to the extensive documentation, even could make you a better programmer. So, to answer the question we didn't ask yet: do we recommend using the PMD jPinpoint rules? The answer to that question is a resounding yes! To be honest, we wish we would have used them earlier, so we didn't have so many already existing violations to fix. Prevention is better than cure, remember?
Acknowledgements
Thanks to Jeroen Borgers for creating the jPinpoint rules and providing me with great feedback for this blog post.
Footnotes
- This is a limitation of the PMD tool that can only look at one class at a time. To determine the immutability of a class is to navigate all classes it refers to in order to determine their immutability (and so forth).
- You could run a mvn clean before running the PMD plugin, so the rules won't trigger on generated code. PMD can also be configured to exclude certain directories from scanning. This way you won't get distracted by code you cannot influence. (Although it might still be interesting to see how performant the auto generated code you use in your project actually is.)