The hyped, happening and happened async programming and streaming frameworks @ bol.com (Part 4)
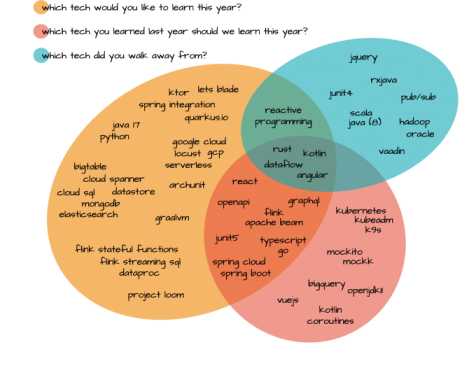
We asked 25 developers, five tech leads and someone “who does unspeakable things with technology” - more commonly known as our principle tech lead which technologies (tools, libraries, language or frameworks) they believe are hyped, happening or happened:
- hyped - which new technologies are you eager to learn more about this year?
- happening - are there any exciting technologies you used last year that we should learn this year?
- happened - did you walk away from any technologies last year?
This is what we got back:
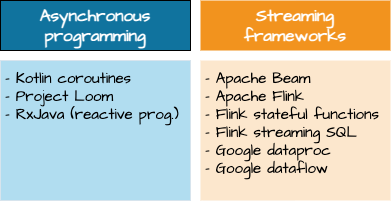
This blog post, which is part of a series of six blog posts in total, we have a closer look at asynchronous programming and data streaming frameworks:
Go to The hyped, happening and happened tech @ bol.com for a complete overview of all the hyped, happening and happened tech at bol.com.
Asynchronous (and reactive) programming
Remember those good (?) old times when we started our compilation job - went for a coffee - and continued the next task only after the compiler finished? Imagine what would happen if we have the same way of working when fetching data from different sources? We live in a microservice world where we have to assemble web pages using different pieces of information coming from a number of different sources. It is 2021, people are impatient and we want our results delivered to our customers within hundreds of milliseconds. So, asynchronous (and reactive) programming - which facilitates us to run multiple tasks in parallel - is still hip and happening today.
Before we can truly appreciate what Java’s project Loom and Kotlin’s coroutines bring, we first need to understand two concepts: lightweight versus heavyweight threading and preemptive versus cooperative scheduling. So, let us explain these concepts first.
Lightweight versus heavyweight threads
To understand what lightweight threads are, let us first understand its opposite: heavyweight threads. When creating a thread in Java, the JVM performs a native call to the operating system (OS) to create a kernel thread. Each kernel thread typically has its own program counter, registers and a call stack - all of which we refer to as the thread’s context. To switch from kernel thread A to kernel thread B is to save the context of thread A and restore the one of thread B. This is usually a relatively expensive - or heavy - operation.
The main goal of lightweight threading is to reduce context switching. It is hard to come up with a crisp definition of what a lightweight (or heavyweight) thread is. Informally we say that the more context involved when switching between threads, the heavier it is.
Preemptive versus cooperative scheduling
It is possible to create more threads than CPU cores, meaning that not all threads can run simultaneously. Consequently, a decision has to be made which thread can run on the CPU when. As you probably guessed there are two ways of scheduling threads: preemptive and cooperative scheduling.
In preemptive scheduling it is the scheduler who decides which thread is allowed to run on the CPU. Threads that are currently running are forcibly suspended and threads that are waiting for the CPU are resumed. The thread itself has no say in when it will be suspended or resumed.
In cooperative scheduling - as opposed to preemptive scheduling - it is not the scheduler who forces the threads to suspend, but the threads themselves control when they will be suspended. Once a thread runs it will continue doing so until it explicitly relinquishes control of the CPU.
Kotlin - coroutines
Kotlin’s support for light-weight threads comes in the form of coroutines. Coroutines allow us to implement asynchronous applications in a fluent way. Before we continue, it is fair to say that Kotlin coroutines offer more than lightweight concurrency, such as channels for inter-coroutine communication. The wealth of these additional constructs might already be a reason for you to use coroutines. However, a discussion of these concepts is beyond the scope of this blog post.
At first glance a coroutine might look very similar to a Java thread. One big difference with Java threads is, however, that coroutines come with programming constructs to explicitly relinquish control of the CPU. That is to say, coroutines are cooperatively scheduled, whereas traditional Java threads are preemptively scheduled.
Coroutines’ cooperative way of yielding control to the CPU enables Kotlin to use kernel threads more efficiently by running multiple coroutines on a single kernel thread. Note that this contrasts traditional Java threads which map one-on-one to kernel threads. This characteristic makes Kotlin coroutines more lightweight than Java threads.
Java - Project Loom
Project Loom aims to bring lightweight threads - called virtual threads - to the Java platform by decoupling Java threads from the heavyweight kernel threads. In that respect project Loom and Kotlin coroutines pursue the same goal - they both aim to bring lightweight threading to the JVM. In contrast to Kotlin coroutines that are cooperatively scheduled, project Loom’s threads remain preemptively scheduled.
Project Loom is still in its experimental phase, which implies that lightweight threads in Java are still not `happening` today. One might ask what project Loom will entail for Kotlin coroutines. Will virtual threads make Kotlin coroutines obsolete? Could virtual threads serve as a basis upon which Kotlin coroutines are built? Or will we be left with two co-existing threading models - virtual threads and coroutines? It is exactly these questions that are also discussed by the Kotlin developer community (see for example the following discussion on the Kotlin forum).
can enable much better performing concurrent code in applications which deal a lot with waiting for I/O (eg. HTTP calls to other systems).
Reactive programming - RxJava
Reactive programming offers yet another way to avoid the costs of switching between different threads. Instead of creating a thread for every task, in the reactive paradigm tasks are executed by a dedicated thread that is run and managed by the reactive framework. Typically, there is one dedicated thread per CPU core. So, as a programmer you don’t have to worry about switching between threads.
Not having to worry about threads and concurrency may sound simple. However, reactive programming is radically different from more traditional (imperative) ways of programming in which we define sequences of instructions to execute. Reactive programming is based on a more functional style. You define chains of operations that trigger in response to asynchronous data. For the ones unfamiliar with reactive programming it helps to think of these chains of operations as Java 8 streams that allow us to filter, map and flatMap items of data that flow through.
Reactive programming frameworks offer more than just operations to manipulate data streams though. The reactive framework selects a free thread from the pool to execute your code as soon as incoming data is observed and releases the thread as soon as your code finished, thereby relieving you from pain points such as threading, synchronization and non-blocking I/O.
Not being bothered with concurrency and all the issues it brings sounds great. However, in our experience reactive programming does increase the level of complexity of your code. As a consequence, your code becomes harder to test and maintain. That is probably the reason why some people are walking away from reactive frameworks such as RxJava.
Data streaming engines
We have access to terabytes of data. Data about which pages our customers visit, which links they click on and which products they order. This information helps us to keep improving our service and to stay ahead of our competition. The earlier we have that information, the sooner we can act upon it.
Data streaming helps us perform complex operations on large amounts of (continuously) incoming data coming from different input sources. Streaming frameworks provide constructs for defining dataflows (or pipeline) for aggregating and manipulating the data in a real-time manner.
Does this all sound abstract to you? Then it might help to visualise a dataflow as something that is quite similar to a Java 8 stream. Because similar to a Java 8 stream we map, filter and aggregate data. The difference is that dataflows process much larger quantities of data than Java 8 streams typically do. Where a Java 8 stream runs on a single JVM, a streaming pipeline is managed by a streaming engine that runs it on different nodes in a cluster. This is particularly useful when the data does not fit on a single machine - something that is true for the amounts of data we process.
Apache Beam and Dataflow
There are many streaming frameworks to choose from, for example Apache Flink, Apache Spark, Apache Storm and Google Dataflow. Each streaming framework comes with its own API for defining streaming pipelines. As a consequence, it is not possible to run, for example, an Apache Flink pipeline on a Google Dataflow engine. To be able to do so you have to translate your Flink pipeline to something Dataflow understands. Only then you can run it on the Dataflow streaming engine.
Apache Beam overcomes this limitation by defining a unifying API. With this API you can define pipelines that run on multiple streaming platforms. In fact, Apache Beam does not come with its own streaming engine. (It offers one for running on small data sets on a local machine.) Instead, it uses the streaming engine of your choice. This can be, amongst others, Apache Flink or Google Dataflow.
At this point you might wonder why we put Dataflow and Apache Beam together. Dataflow is nothing more than a streaming engine to run streaming pipelines. Well, you typically define your streaming pipelines in Apache Beam. This is because Google Dataflow does not come with its own API for defining streaming jobs, but uses Apache Beam’s model instead.
Even though a streaming engine manages the distribution of the data amongst different nodes for you, you’re still tasked with setting up the cluster where those nodes run on, yourself. With Dataflow, however, you don’t have to worry about things like configuring the number of workers a pipeline runs on or scaling up workers as the incoming data increases. Google Dataflow takes all that sorrow away from you.
Flink
Apache Flink - a reliable and scalable streaming framework that is capable of performing computations at in-memory speed - has been satisfying many teams' data hunger for a while now. Its excellently documented core concepts and responsive community are amongst its strong points.
Another advantage is that Flink offers way more functionality than Apache Beam, which has to strike a good balance between portability across different streaming platforms and offered functionality. Flink goes beyond the streaming API you will find in Apache Beam. It offers, for example:
- stateful functions that can be used for building distributed stateful applications, and
- the table and SQL API as an extra layer of abstraction on top of Flink’s data streaming API that allows you to query your data sources with an SQL like syntax.
Why are we still using Apache Beam then? Well, to run an Apache Flink application, you need to maintain your own cluster. And that is a clear disadvantage over Google Dataflow / Apache Beam with which you have a fully scalable, data streaming application running in the cloud in no time. This is exactly the reason why my team chose Apache Beam over Apache Flink a while ago.
Google Dataproc
Google Dataproc is a fully managed cloud service for running:
- Apache Spark
- Apache Flink
- and more (data streaming) tools and frameworks.
That is good news, because this unleashes the power of Apache Flink on the cloud. What would this do with Apache Beam’s popularity? Would we see Apache Flink’s popularity rise at the expense of Apache Beam’s? Well, we can only speculate.
Want to read more about hyped, happening and happened tech at bol.com? Read all about The hyped, happening and happened front end frameworks and web APIs @ bol.com or go back to The hyped, happening and happened tech @ bol.com for a complete overview of all the hyped, happening and happened tech at bol.com.