Services & Autonomy: the one can’t live without the other
Services: automated business processes in small systems, connected through API’s. What started out as a means of technical scalability turned out to be the most important driver of team autonomy – and vice versa. This is our story of Backspin, Rabbits and the Man on the Moon.
From Monoliths to Services
Looking back, 2010 was the year we first realized we were on a path to extinction. Back then we had 4 big monoliths: the catalog & pricing system, the online shop, the order management system and the customer service system. None of these systems had a defined API. If we needed to share data between these systems, we simply duplicated it in a data hub or we directly accessed the data in the other system. We didn’t even have an API to share logic between these systems, so we also had to duplicate a lot of business logic.
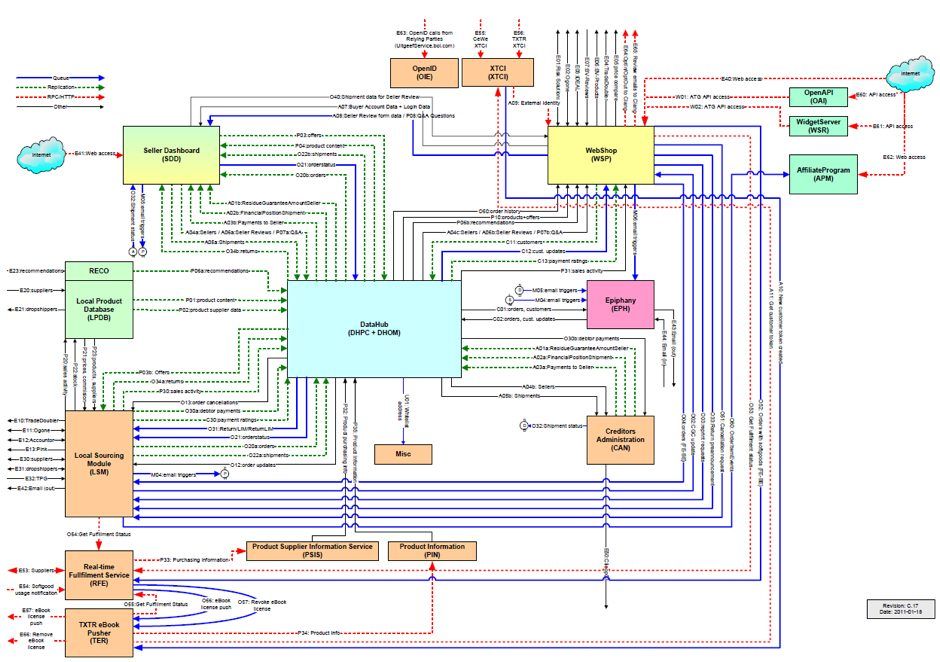
This hub-and-spoke architecture looked fairly simple on paper, but it had grown mighty complex over time. The 4 monoliths were fine when bol.com was an online bookstore but they couldn’t cope with bol.com’s rapid growth into a retail network model where you can buy and sell almost anything. Scalability became a serious issue and the only way to scale was by buying bigger machines. But the real threat was that each monolith was growing into a complex piece of software that could not evolve anymore. And without evolution these monoliths would become extinct.
Our Services Architecture goal
Luckily for us we were not the first and the only ones to run into this problem. An inspiration for us was the CTO of our biggest international competitor: Amazon’s Werner Vogels. In a 2006 interview Vogels explained the IT growing pains of Amazon. His analysis was spot-on. It totally described the situation we were in. Given both the similarities and the success of Amazon and its CTO, Vogels, we decided not to reinvent the wheel but, like Amazon, transform to a service-oriented architecture.
In this service-oriented architecture, each service should have high business cohesion and excel in one important aspect of our business processes. Furthermore the dependency on other services should be low, to avoid ending up with a distributed monolith. Then we could build different business services in parallel, ensuring a faster time to market. And, even more importantly, it would boost the fun and pride in our IT department.
Services, putting theory into practice…
So we took upon ourselves the noble task to re-architecture the bol.com monoliths into loosely coupled, business-driven services. Our catalog & pricing system was the first monolith we tackled. And it was just in time! The processing speed of the system had become slower than the input speed of our suppliers. An update of 2 million prices would take days instead of hours, delaying all other price updates in the process. And by design, this monolith could not scale-up anymore.
We started replacing this catalog & pricing system with 3 services: a service for sourcing and cleaning data from our suppliers, a content service for creating great content and a separate offer service for calculating the best possible combination of price and delivery time.
During this first service-oriented project we learned an awful lot! A services approach was great for handling complex business domains like content & offer management. Splitting up into multiple services reduced complexity and gave us the opportunity to implement each service according to its own unique requirements. We could also assign separate teams to implement and maintain these services and thereby speed up development and time to market.
However, we also learned that working with separate services introduced a whole new set of complexities. Compared to the monolith, we had to put a lot of extra effort into aspects like build management, continuous delivery, automated deployment, regression and acceptance testing, logging and monitoring, eventual consistency, and so on. To address part of this extra complexity we created Backspin, a light-weight framework to implement services. Backspin provided software development teams with a skeleton service, which can be easily plugged into our technical platform capabilities, solving most of the issue around build management, continuous delivery and automated deployment. It really helped us to address part of the extra complexity introduced by building services.
Let’s insource our production environment to enable more speed!
Switching to services in a service-oriented architecture unleashed the creative engineering powers of our software developers. Teams took ownership and demanded more freedom to improve their services.
However, we did not have all that freedom yet because we were not in charge of our production environment. That changed in 2014, when we build our own datacenter and took control over every system, from development to production.
Read more about how we migrated to our new datacenter in our blog post Innovatie bij bol.com. Spoiler alert: hundreds of colleagues helped out with the final acceptance tests at 4:00 a.m.!
Autonomy and DevOps really enabled our Services Architecture
So there we were. We had just invested in our own datacenter and held all the cards in our hands to have team ownership, autonomy and DevOps – in theory at least. In practice, we still had separate Dev and Ops teams. And DevOps didn’t happen automagically. We had to spark it to really get it started. That’s why we came up with our program “Man on the Moon”. This gave a big boost to autonomy and scalability of our IT organization. If you want to know more, check https://techlab.bol.com/agile-journey-far-part-3-build-run-love/.
https://www.slideshare.net/williamderonde3/dev-opsdays-amsterdam-2015-bolpuntcom
The first and most important step Dev teams took in the "Man on the Moon" program was to take control over the release button. No more waiting for OPS to deploy, no more waiting for the 4-weeks (!) release train, no more releasing with downtime (downtime, really??). Instead: releasing by yourself, when ready, whenever you want. Without downtime!
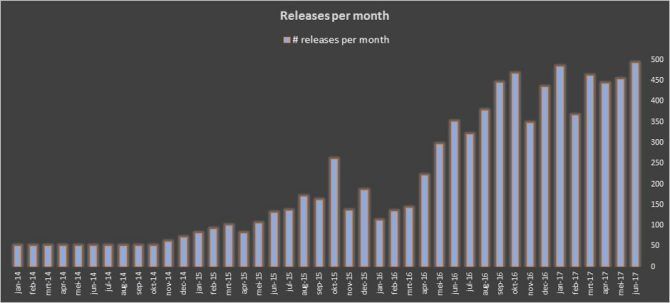
These results and the vibe of the “Man on the Moon” program especially helped the Services Architecture. Deploying a new service or adding new features to a service was way easier than adding functionality to one of the remaining monoliths. We had finally reached the productivity break-even point! By the end of the program new services popped up like rabbits: from 72 at the beginning of 2015 to 300+ at the beginning of 2017.
3 more things to address
So, this was a real breakthrough for the Services Architecture. But we still had to do some work. With the rapid growth of services and all of these services being deployed independently, we ran into the risk of hidden dependencies: services that were not backwards compatible or not resilient to failure of other services. And to be honest, this was not just a risk: every now and then we did encounter downtime due to incompatibility and non-resilience.
Our first solution for this newly discovered complexity was to thoroughly test the specific combination of services and versions before releasing them to production. But that solution was just a glitch of our old way of thinking. One we quickly abandoned for 3 new methods of working: release without downtime, be backwards compatible, and (if all else fails) be resilient. Our whole engineering community agreed on these 3 methods and they quickly become our core technical values. In our current engineering culture, downtime is a shame, compatibility is obvious and resilience is awesome! Working in this way, we can confidently release 100+ times every week.
Services & Autonomy: the one can’t live without the other
Our journey towards autonomy was a real breakthrough for the service architecture at bol.com. But the same holds vice versa! Besides technical scalability, less complex code and less dependencies the real gain was that it enabled team autonomy. And that’s the base of our new mantra: you build it, you run it, you love it!