HPA: how it can save you headaches and money
In this blog, we show you how to automatically scale your application resources according to either the CPU consumption or to the incoming load of your application.
Background
As humans, we are capable of adapting to variable inputs and situations. Some of us are slower, whereas others easily adapt to change. In dynamic environments, flexibility has become one of the most valued skills.
As engineers, we also thrive for adaptability. We embrace new technologies, new responsibilities, and new ways of working together. We want to build future proof solutions that react quickly to changes. Preferably, without manual intervention.
In computer science, autoscaling represents a method highly used in cloud computing, which basically allows computational resources to vary depending on the load on the system.
But what does autoscaling actually bring?
To begin with, it brings better cost management, making sure that you only pay for the resources you need. More importantly, it translates to higher availability, higher throughput and better fault tolerance.
At bol.com, our business has to deal with numerous peaks such as Black Friday - when the load on some systems is 3 times higher than on a regular day. When peaks arrive, you want to ensure that systems can handle them, so you want to scale up. When peak moments have passed, the systems should scale down again, because otherwise it would be a waste of resources (and $$$$$).
The goal of this post is to focus on a tiny part of what the ecosystem of autoscaling is today, which is the Kubernetes Horizontal Pod Autoscaling. While reading this post you will find out more about how HPA works, and about different ways to set up HPA, based on CPU or on custom metrics.
K8s and HPA in a nutshell
There is nicely written documentation regarding Kubernetes and in particular for the Horizontal Pod Autoscaling.
So we will refrain from writing down our own definitions. We will use what is already out there, because who can actually do it better than the creators themselves?
Still, we find it important to clarify the main entities under discussion.
First of all, there is Kubernetes, also known as K8s, which is an open-source system for automating deployment, scaling, and management of containerized applications.
Then there are the pods. Pods are the smallest, most basic deployable objects in Kubernetes. A Pod represents a single instance of a running process in your cluster. Pods contain one or more containers, such as Docker containers.
Furthermore, deployments represent a set of multiple, identical Pods with no unique identities. A Deployment runs multiple replicas of your application and automatically replaces any instances that fail or become unresponsive.
A replication controller ensures that a specified number of pod replicas are running at any one time. In other words, a ReplicationController makes sure that a pod or a homogeneous set of pods is always up and available.
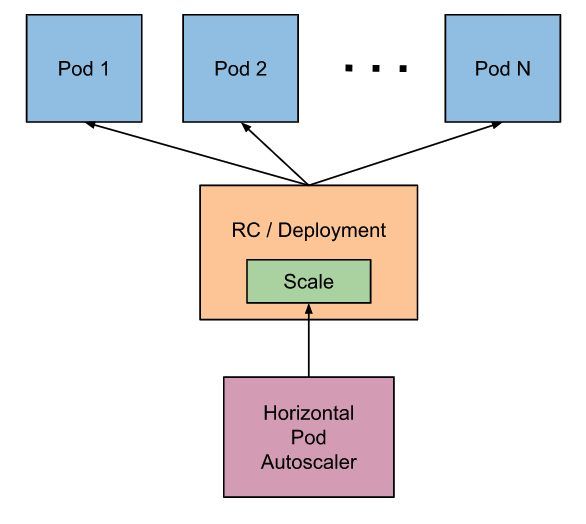
Finally, there is the Horizontal Pod Autoscaler which automatically scales the number of Pods in a replication controller or deployment based on observed CPU usage or, with custom metrics support, on some other application-provided metrics.
The Horizontal Pod Autoscaler is implemented as a Kubernetes API resource and a controller.
In Kubernetes, controllers are control loops that watch the state of your cluster, then make or request changes where needed.
The resource determines the behaviour of the controller. The controller periodically adjusts the number of replicas in a replication controller or deployment to match the observed average CPU usage to the target specified by the user.
Use case
Now that we got some things straight, let us indulge into a specific use case. One of our favourite use cases for using Kubernetes Horizontal Pod Autoscaler is a service called MESS.
MESS (Merchant Express Streaming Service) is the application responsible for sending bol.com product catalog to the Content API for Google Shopping advertisements.
In order to do so, MESS is a streaming service fully running on the Google Cloud Platform. We use the following main technologies: Java, Spring Boot and Kubernetes. Besides this, we also use several managed solutions from the Google Cloud such as Datastore, Pub/Sub, Dataflow templates, and BigQuery.
Basically, the application ingests messages from Pub/Sub - an asynchronous messaging service - from multiple sources in our landscape, such as product content, offers, images. Using this information, MESS forms complete products and sends them to the Content API.
This translates into multiple pods running individually and ingesting messages from different Pub/Sub topics, as shown in the picture below.
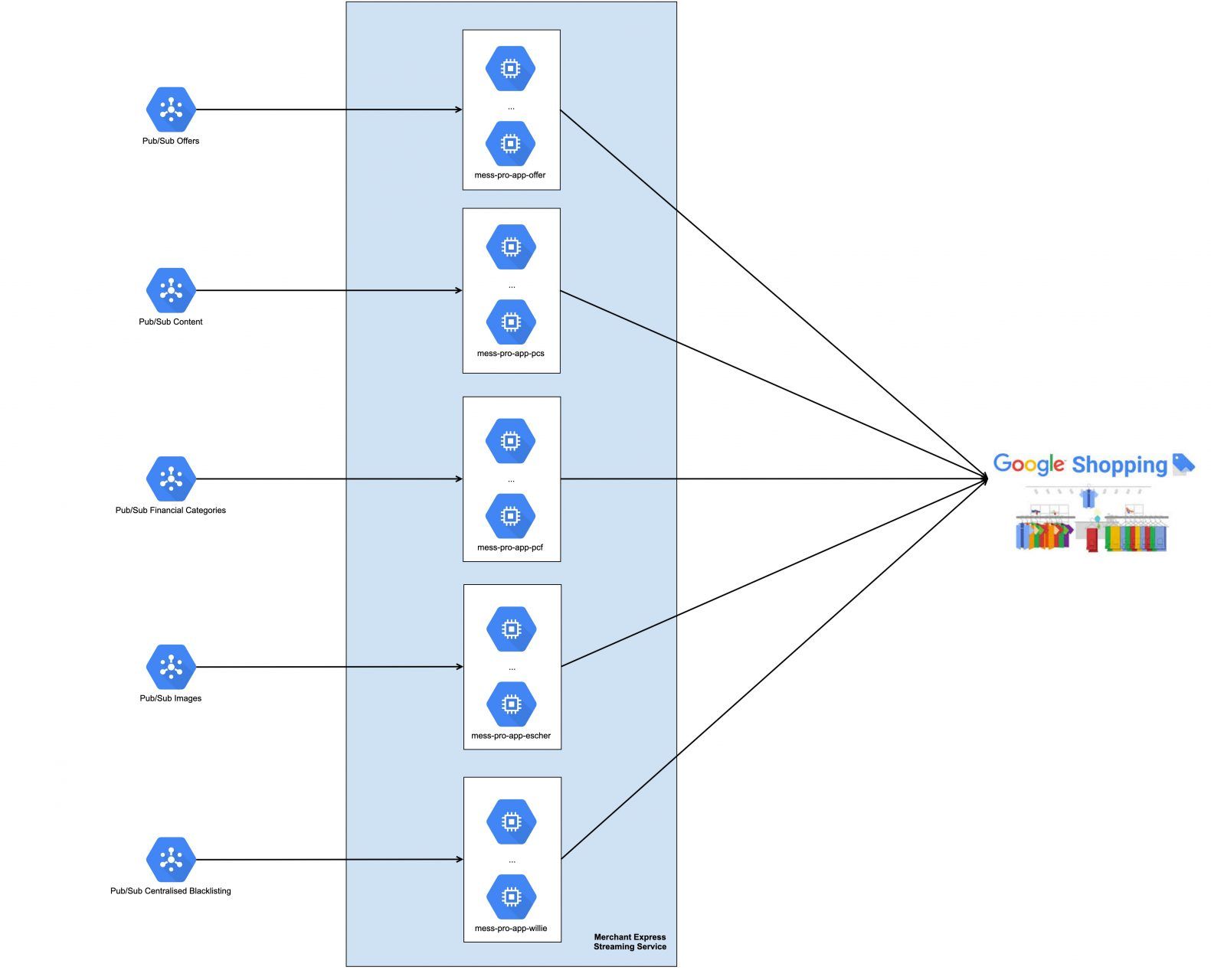
Each input source that MESS connects to can have different behaviour in terms of number of messages, spikes, etc. Offer changes, for example, can add up to 40 million updates/day, bol.com being one of the biggest selling platforms in the Netherlands.
We want to efficiently use the allocated resources and keep up with the incoming messages. Therefore it is important to find a way to configure autoscaling for this system.
First attempt: HPA based on CPU usage
One year ago, we decided to configure k8s HPA based on CPU usage.
First, we looked into the current behaviour of the application and the correlation with the CPU usage. We had to answer important questions. How much CPU is the application using while having a high load on the system? What is the number of minimum pods that we need?
Once we had clear answers, we added the HPA configuration for each flow, as this is different from case to case. For example, for the flow that ingests offer changes we wanted to scale up to maximum 20 pods, from minimum 2 pods, based on target CPU utilization percentage of 50%, as shown below.
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
labels:
app: mess
role: offer
service-name: mess-service
name: mess-scaler-pro-app-offer
namespace: mess
spec:
maxReplicas: 20
minReplicas: 2 (1)
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: mess-pro-app-offer (2)
targetCPUUtilizationPercentage: 50 (3)
(1) The boundaries on how the HPA will scale.
(2) This property is used to specify which kubernetes resource will be scaled. It can be any kubernetes resource that is scalable. In this case it is a Deployment with the name mess-pro-app-offer.
(3) The target value set for the HPA. In this case the application will scale up if the CPU utilization is above 50%.
From the most basic perspective, the Horizontal Pod Autoscaler controller operates on the ratio between desired metric value and current metric value:
desiredReplicas = ceilFor example, if the current metric value is 80% - and the desired value is 40%, the number of replicas will be doubled, since 80.0 / 40.0 = 2.0. If the current value is 20% instead, we'll halve the number of replicas, since 20.0 / 40.0 = 0.5. Scaling will be skipped if the ratio is sufficiently close to 1.0.
Are we there yet?
This setup already sounded better than overprovisioning, but some things triggered our attention:
- While running the application, there are also some CPU peaks that can be confused with an increased CPU usage by the CPU check algorithm. This will translate in pods scaling up and down when there is no actual need to do so.
- The percentage of CPU usage can be affected by various settings, for example the number of threads that the application is using, the total amount of the allocated resources, etc. This means that every time any of these changes occur, the team will need to reevaluate the HPA configuration and fine tune to make it work again.
Both points can eventually lead in having a negative business impact as MESS is sometimes not able to keep up with incoming messages from the landscape (which means wrong content in Google Shopping) or MESS being overprovisioned.
So we were not there yet, but the good news is that there is another way to set HPA that could benefit this use case, so read on!
Second attempt: HPA based on custom metrics
As we were not fully happy with this solution, we kept our interest in improving the setup. Soon, we heard there is a more efficient way to set up HPA, since Kubernetes also added support for making use of custom metrics in the Horizontal Pod Autoscaler.
One can add custom metrics for the Horizontal Pod Autoscaler to use in the autoscaling/v2beta2 API. Kubernetes then queries the new custom metrics API to fetch the values of the appropriate custom metrics.
As mentioned before it is important that MESS keeps up with incoming messages. So which other metric could help more than the Pub/Sub backlog metric?
To base the autoscaling on the incoming messages, we had to:
- make sure that the metrics you want to use are exported correctly;
- look into the behaviour of the application and find out what the maximum throughput for one pod is;
- define the HPA based on the custom metric as follows.
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
labels:
app: mess
role: offer
service-name: mess-service
name: mess-scaler-pro-app-offer
namespace: mess
spec:
maxReplicas: 20
minReplicas: 2 (1)
metrics:
- external:
metric:
name: stackdriver_pubsub_subscription_pubsub_googleapis_com_subscription_num_undelivered_messages (2)
selector:
matchLabels: (3)
project_id: bolcom-pro-mess-ca8
subscription_id: opera-sellingoffer-v1
target:
averageValue: 40000 (4)
type: AverageValue
type: External
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: mess-pro-app-offer (5)
(1) The boundaries on how the HPA will scale.
(2) The metric that is going to be used to determine how to scale.
(3) The labels added to the metric. In this case, this will result in the following Stackdriver metric:
stackdriver_pubsub_subscription_pubsub_googleapis_com_subscription_num_undelivered_messages{project_id="bolcom-pro-mess-ca8",subscription_id="opera-sellingoffer-v1"}(4) The target value set for the HPA. In this case it will mean: for every 40.000 messages on the backlog an additional pod will be added. This value needs to be tuned based on the need of each application.
(5) This property is used to specify which k8s resource will be scaled. It can be any k8s resource that is scalable. In this case it is a Deployment with the name mess-pro-app-offer.
Time for cake
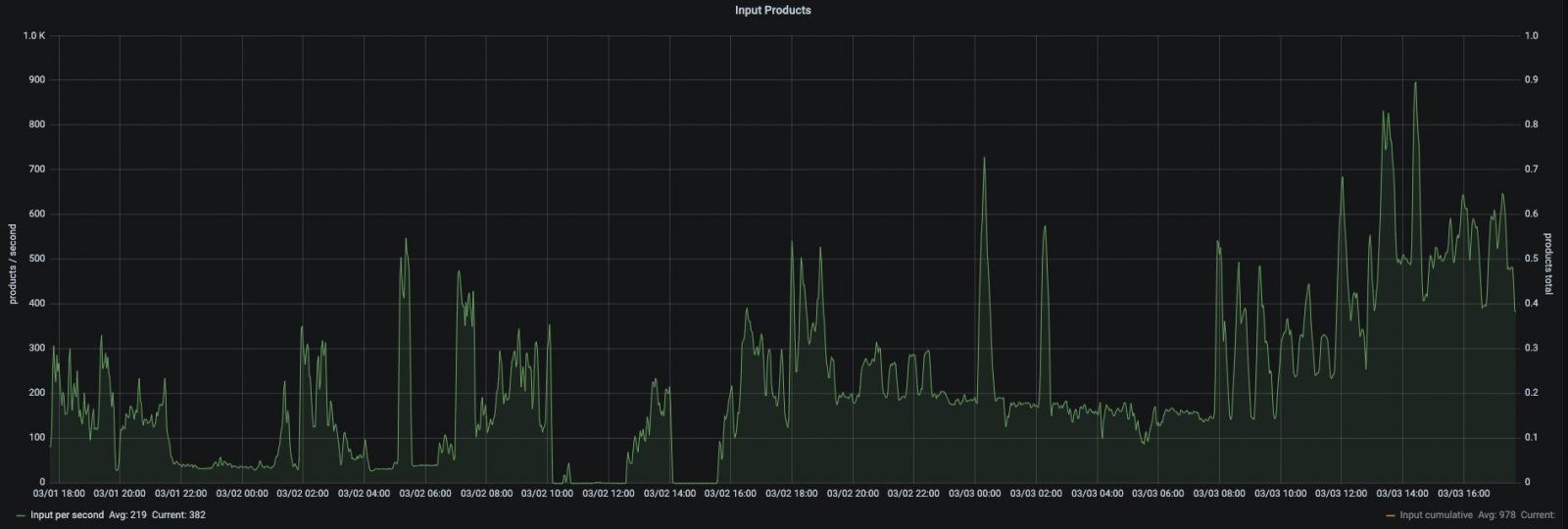
After setting this up for each input source, it was time to see it in action and monitor it. Very rewarding moment to see no queues piling up and the number of MESS pods fluctuating based on the actual load.
Incoming offer changes:
Running MESS pods for offer flow:
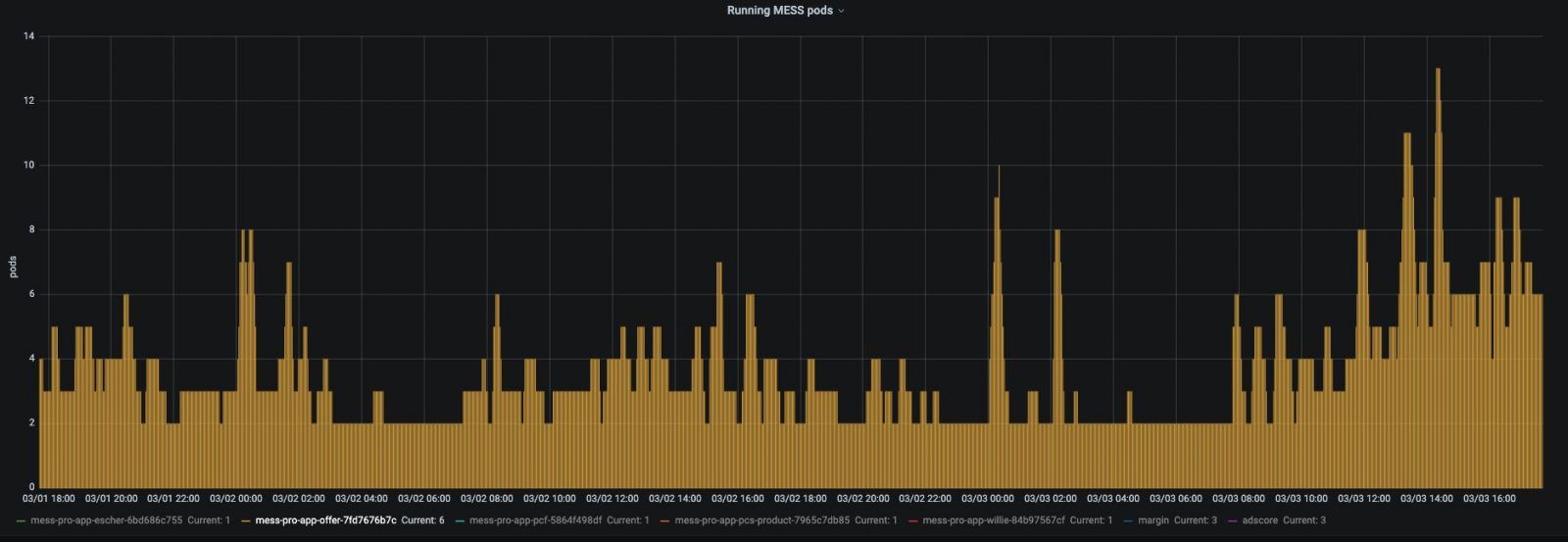
All running MESS pods:
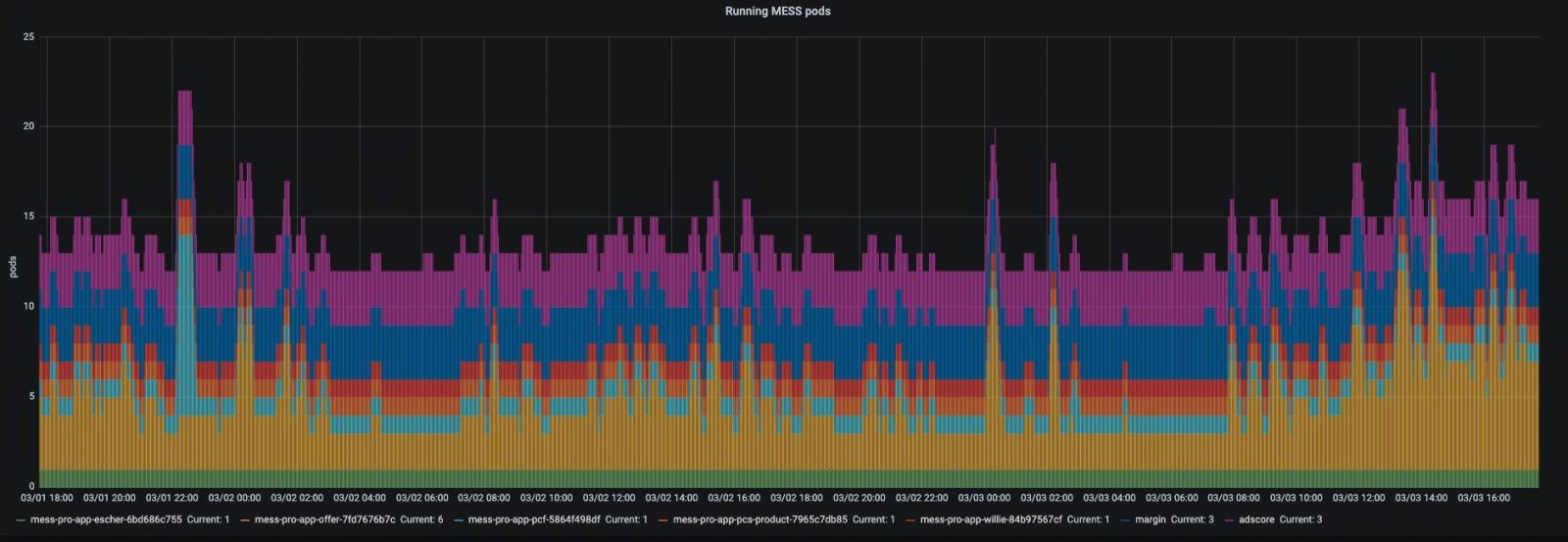
Similar to resource allocation and other application settings, one should revisit the HPA configuration once in a while. This is due to the fact that the behaviour of the application is always changing.
Future improvements
Starting from v1.18, the v2beta2 API allows scaling behavior to be configured through the HPA behavior field. Behaviors are specified separately for scaling up and down in the scaleUp or scaleDown section under the behavior field. A stabilization window can be specified for both directions which prevents the flapping of the number of the replicas in the scaling target. Similarly specifying scaling policies controls the rate of change of replicas while scaling.
Then we could apply a configuration which will allow scaling down more gradually, for example only 20% of pods will scale down every minute if HPA algorithm conditions are met:
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 20
periodSeconds: 60
Conclusion
In this blog, we have shared the journey of setting up Kubernetes Horizontal Pod Autoscaling for MESS. We have shown the evolution of this service. It all started from an overprovisioned service. Then it moved on to a service with HPA based on CPU usage. And finally on to a service with HPA based on Pub/Sub backlog size.
For MESS, using the HPA translates into having the resource usage in line with the load on the system. We don't need to manually scale up during peaks. We also don't need to manually scale down when having regular load. This eventually leads to less money spent and no delays or bottlenecks in the flow.
We consider the capability of setting HPA the cherry on top of the cake. If you want to benefit from this cool feature, you need to put effort upfront into building scalable applications. Think about distributed processing, database interactions, optimizing I/O operations, multithreading, etc.