How (not) to sink a data stream to files? Journeys from Kafka to Parquet.
Last year the Measuring 2.0 team at bol.com has started measuring user behavior on the bol.com website. Of course, we wanted to make the data widely accessible within the whole organization. We had user behavior data in Kafka, a distributed messaging queue, but Kafka is not a suitable data source for every possible client application (e.g. for generic batch processing systems). Given this, we decided to store the historical data in Parquet files which is a columnar format suited for analytics. It seemed like a simple task to sink data from Kafka to Parquet, but we struggled with multiple solutions. In this blogpost I'm going tell you about this struggle.
At first, we created a Flink Streaming job. Flink has built-in tools for reading Kafka, handling out-of-order data, so it seemed like a good fit. However we struggled a lot when trying to fix fault tolerance and finally ended up having a much simpler batch job that reads Kafka and writes it as files to HDFS on a daily basis.
Even if we ditched the results of most of our attempts in the end, we learned a lot along the way. Especially about how fault tolerance works in stream processing. I hope you can learn from our struggle.
Requirements
Reading data from Kafka and writing it to files sounds easy enough. Just listen to the Kafka topics, dump the records to a file, occasionally close the file and open a new one to write new records. But will it scale? What if a failure happens during the process? We had some further requirements:
- Scalable solution.We are talking about 10,000 records/minute and this number is constantly growing as we measure more things and the number of visitors grow. This meant we had to come up with a scalable solution.
- Exactly once.Every record that appears in Kafka must appear exactly once in the files. We don't want to lose data or have duplicates.
- Files in event time.Data in Kafka might be out of order, but we want them ordered in the files. If we created the files based on system time of the processing machines ("processing time"), the file for data between 18:00-18:59 might contain data about a user clicking around at 17:34, or 19:14. We don't want this.
- Columnar format (Parquet).We want to store the data in columnar format. In contrast to a row oriented format where we store the data by rows, with a columnar format we store it by columns. Because the data is so rich, most consumers of the data will not need all columns. By using Parquet, most processing systems will read only the columns needed, leading to really efficient I/O. There will be many consumers of the data, so using a more optimized format pays well.
Again, Flink seemed like a good fit: it's a distributed data processing system (1.), has built in support for Kafka, supports exactly once fault tolerance (2.) and event time (3.), and we were already using it on other projects. It seems easy, huh? Well... we had more trouble than expected.
Solution 1. Windowing
At first, we used the built-in Flink Kafka source and created windows in Flink. The figure shows 1-hour windows.
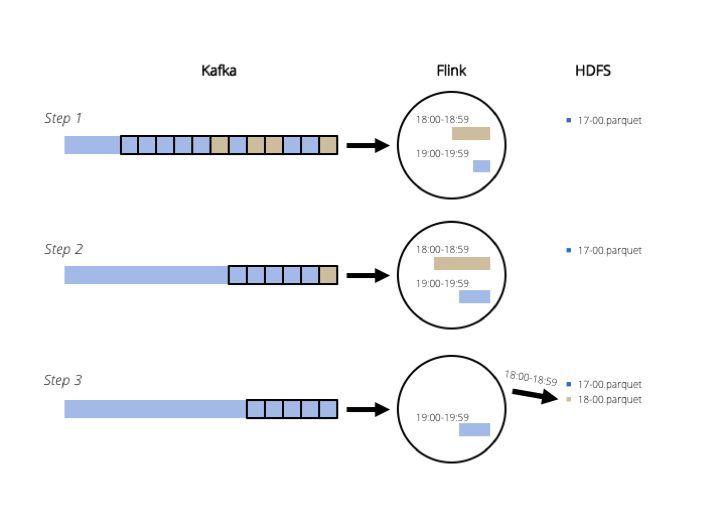
For the sake of simplicity, there is only one Kafka partition in the figure and we're writing one file at once. We can easily generalize it to more partitions, more processing tasks and more output files.
The problem with this approach is that it collects data for 1 hour in Flink state, which is in memory1. So this solution uses a lot of memory and why keep data in memory if we only want to read it and write it? Initially we started with 5-minute files, but if we want 1-hour files we need 12x as much memory. Also if the number of measurements increases by 50%, we need 1.5x as much memory. This does not scale very well, so we started looking at another solution.
Solution 2. Bucketing sink
Fortunately Flink has an interesting built-in solution: bucketing sink. The bucketing sink writes files based on a "bucketer" function that takes a record and determines which file to write it to, then it closes the files when the bucket hasn't been written to in a while. The bucket can be just like a window: we can assign buckets to records and handle event time by only closing the files after they haven't been written to in a while.
Sounds like a much more scalable solution, right? But what if a failure happens? In theory Flink can handle failures for us by making checkpoints and replaying the data from Kafka in case of failure. But we are writing files. If we are replaying, how can we make sure that we don't write the same records twice? The Flink bucketing sink would fix this by marking the size of the files when a checkpoint happens and truncating the file to that size at failure, just as illustrated in the figure.
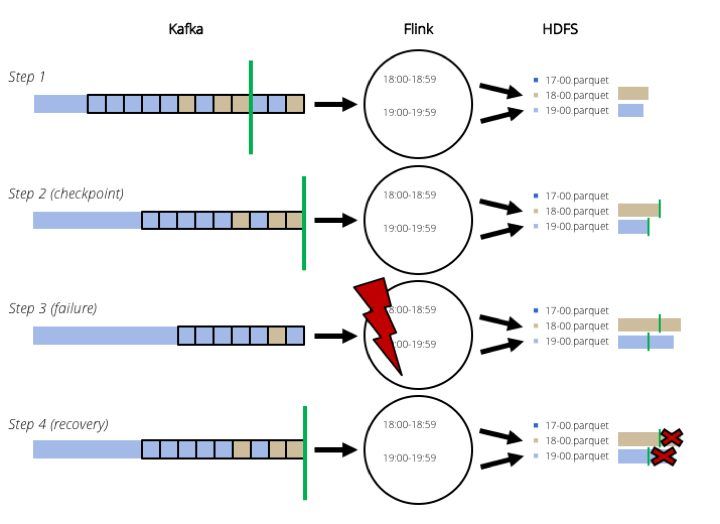
The checkpoint barriers are marked with a green line. To simplify it, that is the time when a checkpoint happens.
That sounds good (as you expected, there is another "but" coming), but there is a problem: we cannot truncate Parquet files. Because it's a columnar format, files are written in blocks and you cannot break these blocks at arbitrary points. What we can do is to close these blocks. At this point we are getting wilder.
Solution 3. Closing files at checkpoint
There is a cool blogpost about how to close a Parquet block at a Flink checkpoint, so that the files can be truncated. It modifies the source code of the Java Parquet writer. If you think that's crazy, you're not alone. But hey, it could work. We took a milder approach: we modified only the Flink bucketing sink to close the files and open new ones at checkpoints (and only at checkpoints). This way, instead of truncating, we can just ignore or delete the partially written files. See the figure.
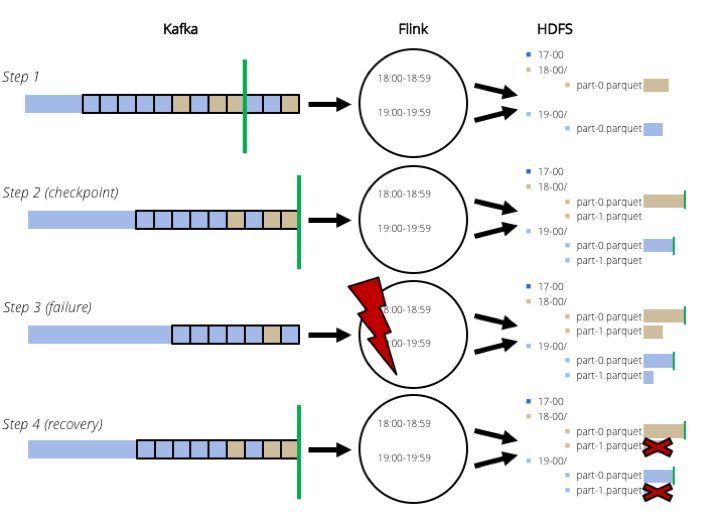
This could be just as good as the above mentioned blogpost. As the efficiency of Parquet is highly dependent on block sizes, closing files instead of blocks should lead to roughly the same performance.
But here comes another "but": we are closing files at every checkpoint, so if there is a small amount of late events for a longer time we are going to have a lot of small files. Having small files on HDFS is bad and consumers might find it hard to handle that (e.g. we get "too many open files" exceptions when trying to process the files with Pig).
So, the quest went on to find a better solution...
Solution 4. Daily batch
As you've noticed, we suffered a lot and had a complicated solution for something seemingly simple. Then, on one day Carst, a team-mate, had the idea: "why don't we just read the Kafka topic from beginning to end and only output the records for the period that we want?" No stream processing system, no complicated fault tolerance, in case of failure we run the job again. So that's what we did. The figure shows the writing for records between 18:00-18:59.
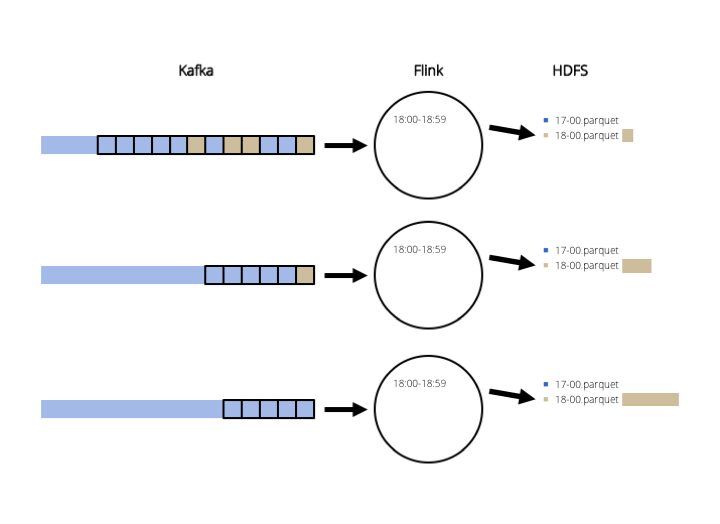
Then, we read the same data again and only write 19:00-19:59.
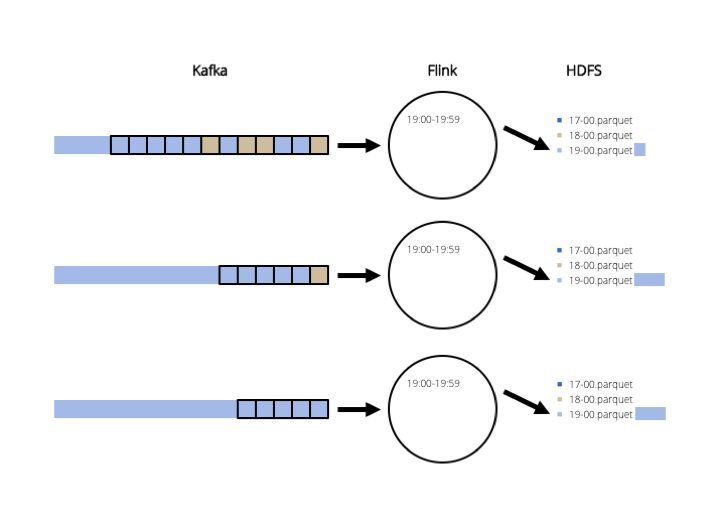
This is way simpler than all the solutions above and it still addresses all our requirements and concerns. We also decided to create daily files. Of course, if you keep one week of data in Kafka, it's not really efficient to read one week of data for writing just one day. But it works, it's relatively simple and we can optimize later. For instance, we can index the Kafka topic by time and only start reading from the first record of the day. As we were using an older version of Kafka that does not support indexing, we just committed the position of the first record of the next day in the Kafka consumer. This achieves the same goal: the next batch will start from the first record of the next day.
Future improvements
One learning is that we should handle our position in the Kafka topic (offsets) and do not let Flink handle it. Flink checkpointing breaks the stream at arbitrary points, thus breaking the files. If we handle the Kafka offsets, we can close the files when we want.
In the end, we could have a more efficient solution in streaming. We could close the files when they're finished and commit offsets to Kafka that are before the first offsets for the currently open files. But this is a bit tricky to solve and the batch solution is good enough for us at this moment.
Conclusion
Doing everything in streaming/real-time sounds cool, but most of the times batch processing suffices and it's simpler. There might be several different solutions to this problem, but why not start with the simplest one and then optimize if needed? However, I cannot say we wasted our time by struggling with these more complex solutions. We learned a lot about how the Flink windowing and checkpointing works and about the columnar Parquet format. I hope this can serve as a learning for others too.
1 Flink does not necessarily keep the state in memory. E.g. the RocksDB state backend flushes some part of the state to disk, but it's basically the same and we don't want to write the data to disk multiple times either.