Empowering autonomous experimentation in a scaling enterprise
Introduction
Like living organisms, companies need to learn and adapt to an ever-changing ecosystem. As a result of that, we are witnessing a paradigm shift in which domain experts are originating important innovations. They are product managers, engineers, analysts, data scientists rather than C-level executives, who still have the important job of facilitating this huge process. Within bol.com we call this paradigm “Product Organization” and this is shaping our way of working for the next few years. A “Product Organization” consists of a cross-functional structure of product teams. Every team focuses on a specific domain like, for example, Logistics or Buying and contains all the know-how from business and IT to innovate on that particular product.
To maximize growth, teams have a high degree of independence within their product boundaries. In Bol.com this translates to a complex service ecosystem maintained by 167 teams over 49 products. As you probably would have guessed from the title of this blog post, we strongly believe that autonomous experimentation is a key element for a scaling enterprise like Bol.com. Experimentation should be a transparent process acting as an enabler for exploration and research. Our goal is aiming at building shared and reproducible insights.
Within Bol.com, Team Experimentation (or Team XPMT in short) facilitates this process. Team XPMT supports a workflow where new ideas and hypotheses are at the core. We preach hypothesis-driven development encouraging teams to come with innovative ideas on their domain and find a way to prove those ideas statistically. Therefore, our mission as Team Experimentation is to reduce time-to-experiment for newcomers.
In this blog post, I would like to tell you about the resources we created and which strategies we applied to enable our colleagues to come up with more and better experiments.
The Experimentation Platform
The distributed nature of IT services makes it harder to establish a link between user interactions and service logic. Therefore, experimenting usually requires additional cross-team coordination. We worked hard in the past years to build an Experimentation Platform that would support our colleagues in bridging this gap.
The Experimentation Platform includes many resources for assisting teams in every step of their experimentation journey. E-learnings, documentation, and articles help to quickly pick up the basics of experiment design and statistics. In addition, it assists colleagues in administering and discovering new experiments.
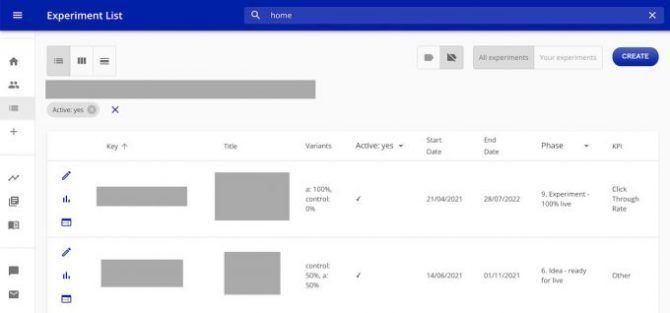
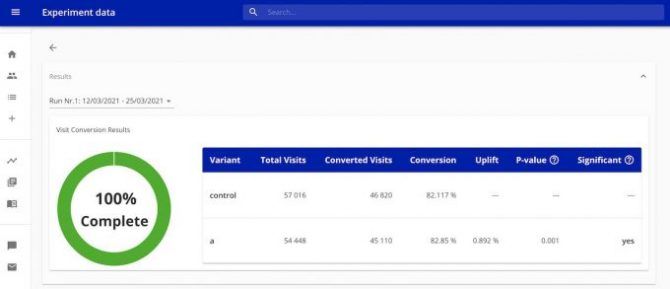
Teams can document experiments with important information like analysis or people and services involved. They can also configure and monitor the status of running experiments. The Experimentation Platform also provides automated dashboards and reports where users can consult several metrics, such as:
- Experiment health metrics to spot early on bucketing issues like imbalances in the traffic split.
- Visit and order metrics to provide a complete picture of the experiment performance.
- Result metrics like conversion or click-through rate,
The Experimentation Library
One of our main objectives is to make experimenting ridiculously easy. Rather than just coming up with a set of guidelines that teams need to follow, we decided to build developer tooling that would ease this process. We created a library that assists the setup of creating ab-tests. Every JVM-based and GO-based application that wants to start running experiments can easily pull the library from the company repository. The library provides two main features: smart bucketing and polling of experiment data.
Smart bucketing
Bucketing is the process of splitting user traffic over multiple experiment variants. To get unbiased results, users should have the same chance to see only one of the variants. The experimentation library provides APIs to perform this reliably. Under the hood, the API hashes the subject identifier and an experiment identifier into a random but deterministic number. This method will fall within a range and every variant is mapped to a portion of the range. As a matter of fact, with this trick, we can consistently assign the same variant to the same user for a certain experiment without the need to store anything. This operation is stateless and idempotent.
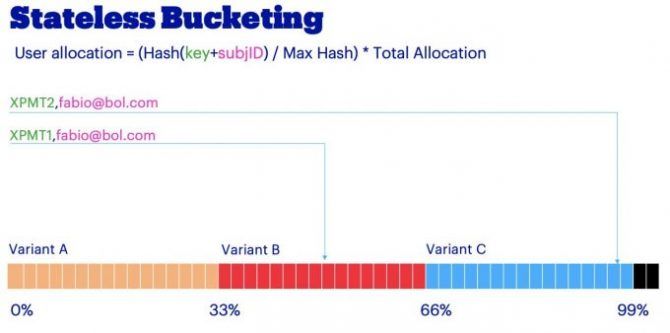
Using an API to perform the bucketing guarantees a lot of flexibility since it can be executed anywhere in the application’s codebase. Developers can choose to trigger the experiment only if certain content is viewed or a process started. For example, they could run an experiment including only users that did not finalize a purchase. This allows defining a tighter experiment scope reducing noise in the data. We call this approach smart bucketing since it allows for the design of more effective experiments.
Polling of experiment data from the Experimentation Platform
The Experimentation Library includes a client that will poll for any updates on experiments added on the Experimentation Platform. It will store any change of state locally within the service. In this way, the service will execute the bucketing without the need to rely on additional network calls. This guarantees that services using the Experimentation Library are not tightly coupled to the Experimentation Platform backend. If the Experimentation Platform is unavailable, the service will still be able to serve user requests without additional latency.
Measuring the results
Once a service assigns an experiment variant to a user, it should record the user's reaction. The user will interact with the variant clicking, typing, or scrolling around. These interactions are stored in measurements. A measurement is a snapshot that captures all interesting information about interactions within that user's session. The frontend service generates an initial measurement before rendering the content. Consequently, it enriches it with more data when new actions in the frontend are executed. Therefore, the frontend service should establish a link between the activated variant and the measurements because we need to be able to recognize which measurements are a consequence of an experiment.
{
"timestamp": 1624452822618,
"session": {
"deviceId": "h6lcaqv9gjuy8d0hv0bqbuhdk1uf7e5j",
"sessionId": "87de8fbb-be58-4155-80a2-0c6daed2bff6",
"visitId": "1ts2+6LpRYI4wEGVf/0TFeH8HLpgiX0OyanRMOHf0so",
"applicationSessionId": "9ff239bb-1cde-4efa-8231-e8c7838b6715",
},
"event": {
"container": {
"event": "RENDER",
"details": {
"containerType": "PAGE",
"page": {
"name": "Home"
}
}
},
"group": {
"event": "RENDER",
"activeABTests": <
"XPMT1_a",
"XPMT4_a",
"XPMT4_control"
>
}
}
}This is an example of an extract of measurement. The field “activeAbTests” contains all the assigned variants. Considering that every request produces at least one measurement, a large constant stream of measurement is fed into a Kafka Cluster. This massive amount of data is eventually stored in a data warehouse such as BigQuery.
Daily a batch job filters and crunches down this data into a digestible dataset that can be easily queried and displayed on our dashboards.
Serving distributed experiments
We strive to empower every team in being able to experiment with new ideas independently. Though, realistically their services need to operate in a complex ecosystem. Often their services are deep in the call chain, many "hops" away from the frontend. For this reason, in the past, multiple teams had to be involved to set up an experiment despite the experiment idea was coming from just one team. We had to iterate our approach to get to a way of working that was ideal for us.
A simple approach
Our initial approach in serving distributed experiments was quite simple. The experiment service should bucket the user in one of the variants and inform the frontend in the response.
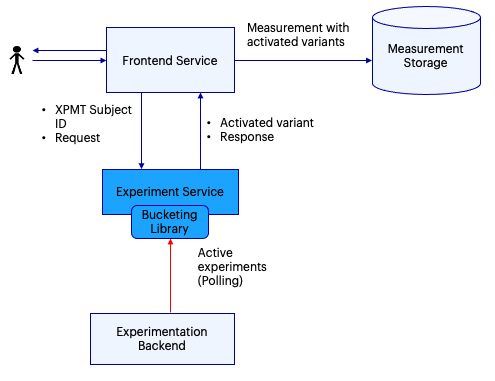
In the image, we see the experimenter service polling to learn about new experiments from the Experimentation Platform backend.
The experiment service will bucket all user requests for every new active experiment. Once variants are assigned the service will communicate them back to the frontend. Before rendering the content, the frontend will link the activated variant to any related measurement.
Unfortunately, we found out quite soon that this approach had a few technical limitations. Since only frontend services can publish measurement data, they need to get the activated variant back from the response. In the case of async requests, sending back the variant is harder because a response may not be present.
Moreover, we faced another serious issue on an organizational level. Various teams maintain backend and frontend services. Teams depended on frontend teams to set up an experiment. A simple experiment could lead to lengthy discussions over prioritization, especially when teams were part of different products, they ended up postponing new experiments or simply canceling them.
A better approach
We were in desperate need to find ways to enable the teams to experiment more independently. Therefore we went back to the drawing board to come up with a strategy to tackle this organizational bottleneck. To address these concerns, we decided to decouple experiment variants from the frontend measurements. We introduced a new concept called XPMT Beacon. The XPMT Beacon acts as a linking pin between the activated variants in a request and the measurements.XPMT Beacon = {XPMT Beacon ID, Activated Variant}
{
"transport": {
"XPMTBeaconID": "aceeda81-d2bc-41cc-a4db-adbb84d4b906"
},
"timestamp": 1624452822618,
"session": {
"deviceId": "h6lcaqv9gjuy8d0hv0bqbuhdk1uf7e5j",
"sessionId": "87de8fbb-be58-4155-80a2-0c6daed2bff6",
"visitId": "1ts2+6LpRYI4wEGVf/0TFeH8HLpgiX0OyanRMOHf0so",
"applicationSessionId": "9ff239bb-1cde-4efa-8231-e8c7838b6715"
},
"event": {
"container": {
"event": "RENDER",
"details": {
"containerType": "PAGE",
"page": {
"name": "Home"
}
}
},
"group": {
"event": "RENDER"
}
}
}We modified the measurement removing the field “activeAbTests” and adding a new field “XPMTBeaconID”. This field will contain an identifier randomly generated per request (UUID) assigned to every measurement produced within that request. Services will now use this identifier to publish updates on the user's current experiment bucket. In other words, the frontend service will store an XPMTBeaconID within the web measurements to logically connect frontend user actions to the experiment context.
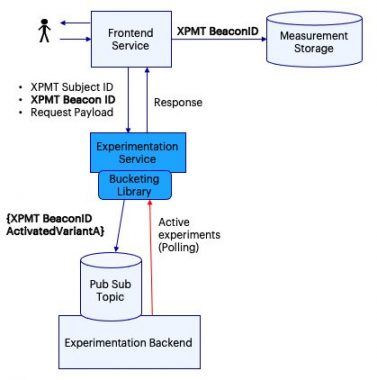
To enable this pattern, we made a few changes to the approach mentioned above. Firstly, the frontend service generates a Beacon ID for each request. Right before rendering the content to the user, the frontend service maps that ID to the measurements and forwards it to all services that want to do experiments. The experimenter service fetches the Beacon ID and the Subject ID from the request, executing the bucketing when in scope. The service will then return its normal response. At the same time, it will also publish the activated variants on a pub-sub topic.
A streaming job will listen to updates on the topic, copying them over a database. Eventually, a daily job will merge the activated variant back to the measurement data. A team setting an experiment will just need to ask other teams to correctly forward the BeaconID and make sure to publish the result of the bucketing. For the rest, they can just focus on what matters to them: build cool new features!
It's good to mention that requiring other services to forward the Subject ID and Beacon ID is also a dependency. However, this can be easily automated. With distributed tracing tools, it is possible to indicate request headers to automatically forward. Subject ID and Beacon ID could just be passed around as experimentation headers.

Handling beacons from the Experimentation Library
To accommodate the support of beacons, we extended the Experimentation Library with two new features:
- Automatic fetching of beacon ID from the request
- Automatic publishing of activated variant
In the next code example, I'll show how teams can use spring magic to set a request-scoped instance of the experimentation client. The Experimentation Library allows injecting an ExperimentationClientRequestScoped object that holds a Beacon ID received for that request. ExperimentationClientRequestScoped exposes the method getActiveVariantAndSendBeacon that executes bucketing and publishes the result on a topic. After this call is made, the service should just return to the frontend the response related to the selected variant.
@RestController
@RequestMapping("/api/")
@ApiGroup("example")
public class ExampleController {
private final ExperimentationClientRequestScoped experimentationClientRequestScoped;
@Autowired
public ExampleController(ExperimentationClientRequestScoped experimentationClientRequestScoped) {
this.experimentationClientRequestScoped = experimentationClientRequestScoped;
}
@GetMapping("/demo1")
@ResponseBody
@ResponseStatus(HttpStatus.OK)
public String tryExample(@RequestParam String subjectId) {
String variant = experimentationClientRequestScoped
.getActiveVariant("xpmt-hello-world", subjectId)
.map(Variant::getKey)
.orElse("Experiment Not Active");
return variant;
}
}Concluding
Experimenting in a scaling enterprise can show bottlenecks when services heavily depend on each other. Within Bol.com, we addressed this challenge making autonomy a first-class citizen in experiment design. It was a bumpy road but it allowed us to learn a lot about how to empower teams with experimentation superpowers.
However, our journey in bringing experimentation within bol.com to the next level is only at the start. We are constantly working on finding new strategies to lower the barrier to experimentation but also improving the quality of experiments outcome. Stay tuned for more!
If you enjoyed the article, feel free to check this video where I talk about the same topic. You may also find this podcast interesting. In the podcast, two members of Team XPMT, our product manager and our software architect give their perspectives on the achievements and the challenges of preaching experimentation within the company.
Last, but not least, I am extremely proud to share that Team XPMT won the experimentation culture awards of the year 2021.
For any questions regarding experimentation on Bol.com feel free to reach the Product Manager of Team XPMT Denise Visser (dvisser@bol.com).